.svg)


.png)
.png)




There are now dozens of AI red-teaming tools on the market. Vendors publish feature matrices, probe counts, and compliance badges. But if you've tried more than two of them, you already know: the feature list tells you almost nothing about whether a tool will actually find the vulnerabilities that matter in your AI application.
We've spent the last four years building and using AI red-teaming tools at Giskard. We've also watched the market closely - what works in production, what doesn't, and where teams get stuck. This guide is our honest take on how to evaluate AI red-teaming solutions in 2026, and where each major tool fits.
Why comparing AI red teaming tools is harder than you think
Most benchmark articles line up tools side by side and count features. That doesn't work here. Unlike traditional application security, where you can run tools against a known vulnerability database and measure detection rates, AI red-teaming deals with failures that are deeply context-dependent: tied to your specific use case, your data, your users, your domain. A scanner that surfaces 200 issues on a demo chatbot may miss the one hallucination that costs your company a lawsuit.
Before you evaluate any vendor, you need to get clear on four questions. These will determine which tool actually fits your situation, and which ones are solving a different problem than yours.
Question 1: Does the tool treat security and quality as inseparable?
Most AI red-teaming tools started life as security scanners for cybersecurity teams. They test for prompt injection, jailbreaks, data exfiltration - the OWASP LLM Top 10. These are real risks that deserve attention.
But security and quality for AI systems cannot be evaluated separately. Two observations drive this conviction.
First, the boundary between them is structurally blurry. Many failure categories - sycophantic behavior, off-topic responses, controversial statements, unjustified refusals - sit right at the intersection. An unjustified refusal is simultaneously a quality problem (bad user experience) and a security signal (a guardrail miscalibrated so aggressively that, if crudely "fixed," could open new vulnerabilities). Treating these in separate silos leads to incoherent trade-offs.
Second, over-filtering is a real and underestimated risk. An agent that blocks everything isn't "secure" - it's unusable. The real value of rigorous evaluation lies in finding the calibration that protects the brand without degrading the experience. That requires testing security and quality together, in the same loop, with the same tool.
The tools that separate these concerns (security team runs one scanner, AI team runs another) create blind spots at exactly the point where the hardest decisions are.
Question 2: Is the tool built for agents, or for models?
This is the question that separates 2024-era tools from 2026-era ones. Most red-teaming frameworks were designed to test foundation models: send a prompt, evaluate the response. But production AI in 2026 is agentic: it calls tools, queries databases, orchestrates multi-step workflows, uses MCP servers, and makes autonomous decisions.
Red-teaming an agent requires two capabilities that model-level scanners simply don't have.
Global Evaluation - not just checking the output, but the entire dynamic of the interactions. When you red-team a model, you look at what it says. When you red-team an agent, the output might just be "DONE" - the real information is in what the agent did: which function it called, what arguments it passed to write_database, what permissions it requested. You also need to evaluate each interaction in the context of all previous interactions, because the context that makes an action dangerous often lies in the conversation history, not in the action itself.
Global Simulation - not just generating user messages, but mocking the full environment. Model red-teaming generates adversarial user prompts. Agent red-teaming needs to simulate particular system states (tool outputs), and construct entire conversation flows - sequences of user messages, tool calls, and tool responses - designed to push the agent into failure modes. It's about mocking the right situation holistically: user messages combined with tool call results and interaction sequences that expose vulnerabilities no single prompt could trigger.
A tool that red-teams GPT-4 with single-turn prompts will miss the vast majority of real-world vulnerabilities in an agentic application. The OWASP Top 10 for Agentic Applications (2026) classifies Agent Goal Hijack as ASI01 and Tool Misuse as ASI02 - the two highest-priority risks - and single-turn scanners cannot detect either.
Question 3: Does the tool help you fix issues, or just detect them?
Detection is the easy part. The hard part is what happens after the scan.
Most red-teaming tools generate a report: here are 47 vulnerabilities, sorted by severity. Then what? Your team opens tickets, tries to reproduce the issues manually, argues about priority, and eventually patches a few of them before the next release. By then, the model has been updated, the prompt has changed, and you don't know if the old fixes still hold.
The tools that actually improve your system do three things with every discovered vulnerability:
Turn vulnerabilities into prioritized tasks: with severity scoring, assignment, and tracking. Red-teaming shouldn't end with a PDF; it should feed into your team's workflow as actions.
Turn vulnerabilities into regression tests: so that every fixed issue stays fixed. When you change a prompt, swap a model, or update your RAG sources, your regression suite catches regressions automatically. This is the difference between "we scanned once" and "we have continuous assurance."
Turn vulnerabilities into guardrails: so you can patch the most critical issues immediately at runtime, even before fixing the root cause.
Without this fix-oriented pipeline, red-teaming becomes a pointless checkbox exercise - you know you have problems, but you can't systematically resolve them.
Question 4: Is the tool a product, or a process?
This might be the most underrated question, but the one that determines whether red-teaming actually changes anything in your organization.
Most tools treat red-teaming as a product: install the scanner, run the probes, get the report. But effective red-teaming is a process. It requires translating your specific business requirements (your regulatory context, your domain risks, your acceptable failure modes) into a testing configuration that reflects how your AI actually gets used. No generic scanner can do that out of the box.
The best platforms don't just give you a CLI tool and wish you luck. They help you onboard your domain context into the tool: what does a dangerous hallucination look like in your industry? Which failure modes are compliance-critical versus merely annoying? What attack scenarios reflect your actual threat model? Then they operationalize it: automatically opening tasks when new vulnerabilities surface, routing findings to the right team members, feeding an improvement loop to add agent-specific guardrails at runtime.
Enterprise domain knowledge is the differentiator. Automated scanners can find that your agent is vulnerable to a particular prompt injection technique. But only someone who understands your business - a doctor, a compliance officer, a financial analyst - can judge whether a particular hallucination is dangerous or trivial, write attack scenarios that reflect real-world abuse patterns, and prioritize issues based on business impact rather than technical severity. The platforms that get this right embed human expertise into the loop: interactive playgrounds for exploring agent behavior, collaborative workflows for cross-functional teams, and feedback mechanisms where every human insights improves the next automated scan.
Red-teaming that stays a "tool" delivers reports. Red-teaming that becomes a "process" delivers outcomes.
The 2026 landscape: 9 AI red teaming tools compared
With these four questions as our evaluation framework, here's how the leading tools stack up.
1. Giskard – Best for agent red teaming that covers security and quality, fixes Issues, and adapts to your domain (🇪🇺 France)
What it is: Giskard is an AI red-teaming and evaluation platform that tests security and quality together, provides agent-native testing , turns vulnerabilities into prioritized tasks, regression tests & guardrails (blue teaming), and adapts to your enterprise domain context through a managed service approach. It offers both an open-source Python library and an enterprise platform (Giskard Hub).
Why it stands out in 2026:
Giskard is built around the four principles outlined above - and we say that not because we wrote them to match our tool, but because we built the tool after learning these lessons the hard way, running continuous red-teaming for public-facing AI applications deployed to millions of end-users by many enterprises across Europe.
On security and quality, Giskard's 50+ specialized probes span the full OWASP LLM Top 10, but also hallucination, sycophancy, off-topic, over-refusal, and reputational & legal checks. Security and quality are tested together, in the same scan, surfacing the trade-offs between them rather than hiding them in separate reports.
On agent-readiness, Giskard's scanner deploys autonomous red-teaming agents that conduct dynamic, multi-turn attacks across 50+ probe types. It evaluates not just system outputs but tool call arguments and interaction history - the global evaluation and global simulation approach described above. The engine includes techniques like GOAT (Generative Offensive Agent Tester) for adaptive multi-turn jailbreaking, and adapts in real-time to the target's responses, escalating attack strategies to probe grey zones where defenses typically fail.
On fixing - not just detecting - every discovered vulnerability flows into a three-part pipeline: prioritized tasks assigned to team members, regression tests that run automatically in CI/CD, and a dedicated guardrails module for runtime patching. When your model changes, your prompt changes, or your RAG sources change, you know instantly whether previous fixes still hold.
On integration with domain expertise, Giskard Hub provides an interactive playground for exploring agent behavior, collaborative scenario design for domain experts, team discussion and task assignment for discovered issues, and a feedback loop where manual red-teaming insights sharpen automated scans.
Key strengths:
- Security + quality tested together
- Agent-native: evaluates tool calls, interaction history, and conversation flows - not just text outputs
- Vulnerabilities → guardrails + prioritized tasks + regression tests
- Domain adaptation: onboards your enterprise context, risk profile, and compliance requirements into testing configuration
- Collaborative platform with interactive playground, team workflows, and business-friendly UI
- Adaptive multi-turn red-teaming with GOAT and 50+ probes
- OWASP LLM Top 10 and NIST AI RMF alignment
- CI/CD integration for continuous testing
- Open-source library + enterprise hub
- European company (France), with real EU data sovereignty posture
Limitations:
- Focused on text-based AI applications (no image/audio red-teaming yet)
- Enterprise features require Giskard Hub (not available in the OSS version alone)
Pricing model: Open-source library (free) + Enterprise Hub (custom pricing for teams). This hybrid model gives individual developers full access while enabling team-scale collaboration.
Best for: Organizations that need end-to-end red-teaming covering security and quality together, want to fix issues (not just detect them), and need agent-native testing with cross-functional collaboration.
2. Promptfoo - Best for developer-centric CI/CD red teaming (🇺🇸 USA)
What it is: Promptfoo is an open-source CLI and library for evaluating and red-teaming LLM applications, popular among developers for its YAML-based configuration and tight CI/CD integration. Promptfoo was acquired by OpenAI in 2025.
Why it matters:
Promptfoo is the developer's red-teaming tool. If you live in pull requests and GitHub Actions, its declarative test configs and fast iteration cycles feel natural. It covers 50+ vulnerability types, supports OWASP and NIST presets, and generates adversarial inputs using AI rather than relying only on static datasets.
It recently added agent red-teaming capabilities and an MCP plugin for testing tool-calling vulnerabilities, which shows awareness of the agentic shift.
Key strengths:
- Excellent CI/CD integration with fast feedback loops
- AI-generated attacks tailored to your specific application
- YAML configuration - no heavyweight setup
- Strong open-source community
- MCP vulnerability testing plugin
- Multi-provider support (OpenAI, Anthropic, Mistral, Azure, etc.)
Limitations:
- Acquired by OpenAI - raising independence concerns for teams that need a vendor-neutral evaluation tool. When your red-teaming tool is owned by an LLM provider, questions about objectivity and long-term neutrality are inevitable.
- Primarily a developer tool - limited collaboration features for non-technical stakeholders
- Quality-focused testing (hallucination, sycophancy) is less mature than security testing
- No business-friendly UI for domain experts to contribute scenarios
- Limited vulnerability-to-fix pipeline (no task management)
- No European data & AI sovereignty
Pricing model: Open-source core (free). Enterprise cloud offering available.
Best for: Engineering teams who want red-teaming integrated into their CI/CD pipeline and are comfortable with CLI-first workflows - keeping in mind the OpenAI ownership implications.
3. NVIDIA Garak - Best Open-Source probe library for model-level testing (🇺🇸 USA)

What it is: Garak is NVIDIA's open-source LLM vulnerability scanner - it probes models for hallucination, data leakage, prompt injection, toxicity, and 120+ vulnerability categories.
Why it matters:
Garak has the most extensive static probe library on the market. If you need breadth of known-vulnerability coverage against a foundation model, it's hard to beat. It supports nearly every model provider and format, from Hugging Face to REST APIs to GGUF files.
Key strengths:
- 120+ vulnerability categories - the broadest probe library available
- Model-agnostic (Hugging Face, OpenAI, Bedrock, REST, GGUF)
- Strong research pedigree (published academic paper)
- Fully open-source
Limitations:
- Designed for model testing, not agent testing - no tool-calling or MCP support
- Primarily single-turn, static attacks - limited adaptive or multi-turn capabilities
- The automated attack generation (atkgen) module is a prototype, mostly stateless
- No collaboration or workflow features
- Full scans are resource-intensive (thousands of LLM completions per run)
- No vulnerability-to-fix pipeline
Best for: Research teams and security engineers who need maximum breadth of known-vulnerability scanning on foundation models.
4. Microsoft PyRIT - Best for Azure-integrated security team workflows (🇺🇸 USA)
What it is: PyRIT (Python Risk Identification Toolkit) is Microsoft's open-source framework for red-teaming generative AI systems, focused on security professional workflows.
Why it matters:
PyRIT comes from Microsoft's internal AI Red Team - one of the most experienced in the world. It provides a structured methodology for AI red-teaming with attack orchestrators, scorers, and converters that can be composed into multi-step attacks.
Key strengths:
- Built by Microsoft's internal AI Red Team with deep expertise
- Highly customizable attack pipelines (orchestrators, scorers, converters)
- Native Azure integration
- Good documentation and structured methodology
- Full access to attacker and evaluator LLM configurations
Limitations:
- Synthetic data only (not representative of real-world data distributions)
- Limited sandboxing for agentic testing - mock tools don't support behavior mocking
- Requires significant Python expertise to operate effectively
- No collaborative features or business-user interfaces
- No vulnerability-to-fix pipeline
Best for: Security teams in Microsoft/Azure environments who want a customizable Python framework and have the engineering capacity to build their own workflows.
5. Confident AI DeepTeam - Best for Python native red teaming with guardrails (🇺🇸 USA)
What it is: DeepTeam is Confident AI's open-source framework for red-teaming LLMs and LLM systems, offering vulnerability detection, adversarial attacks, and production guardrails in a single package.
Why it matters:
DeepTeam bridges red-teaming and runtime protection. It detects 40+ vulnerabilities using 10+ research-backed attack methods, and includes 7 production-ready guardrails for real-time input/output filtering. Its agentic red-teaming module provides 16 specialized vulnerabilities across 5 critical areas for autonomous systems.
Key strengths:
- 40+ vulnerabilities, 10+ attack methods in a clean Python API
- 7 built-in guardrails for production deployment
- Dedicated agentic red-teaming module with authority spoofing, role manipulation, and goal redirection
- OWASP, NIST, and MITRE ATLAS framework alignment
- Active open-source community
Limitations:
- Python-only - no web UI or collaborative platform
- Limited multi-turn adaptive capabilities
- Guardrails are separate from the evaluation pipeline
- No enterprise collaboration or workflow features
- No European data & AI sovereignty
- Newer entrant - less battle-tested at enterprise scale
Best for: Python-centric teams who want red-teaming and guardrails in a single library with a clean API.
6. Splx AI - Best for end-to-end AI security with runtime protection (🇺🇸 USA)

What it is: Splx (now acquired by Zscaler) is an AI security platform that combines automated red-teaming with runtime guardrails, prompt hardening, and compliance reporting.
Why it matters:
Splx takes a full-lifecycle approach: red-team to find vulnerabilities, then automatically harden your system prompts and deploy runtime guardrails. Their Agentic Radar is the first open-source security scanner specifically for agentic AI workflows, visualizing attack surfaces and surfacing tool-level vulnerabilities.
Key strengths:
- Red-teaming + automatic remediation (system prompt hardening reduces attack surface by up to 95%)
- 25+ predefined and custom risk categories
- Agentic Radar for visualizing agentic workflow vulnerabilities
- Runtime guardrails for production deployment
- NIST AI RMF, OWASP, and EU AI Act compliance mapping
Limitations:
- Acquired by Zscaler - product continuity and roadmap post-acquisition remain unclear
- More security-focused than quality-focused (limited hallucination/sycophancy testing)
- No European data & AI sovereignty
- No open-source core offering since acquisition
- Less mature multi-turn adaptive attack capabilities
Best for: Enterprise security teams wanting an integrated red-team-to-remediation pipeline with runtime protection.
7. Mindgard - Best for enterprise managed AI security services (🇺🇸 USA)
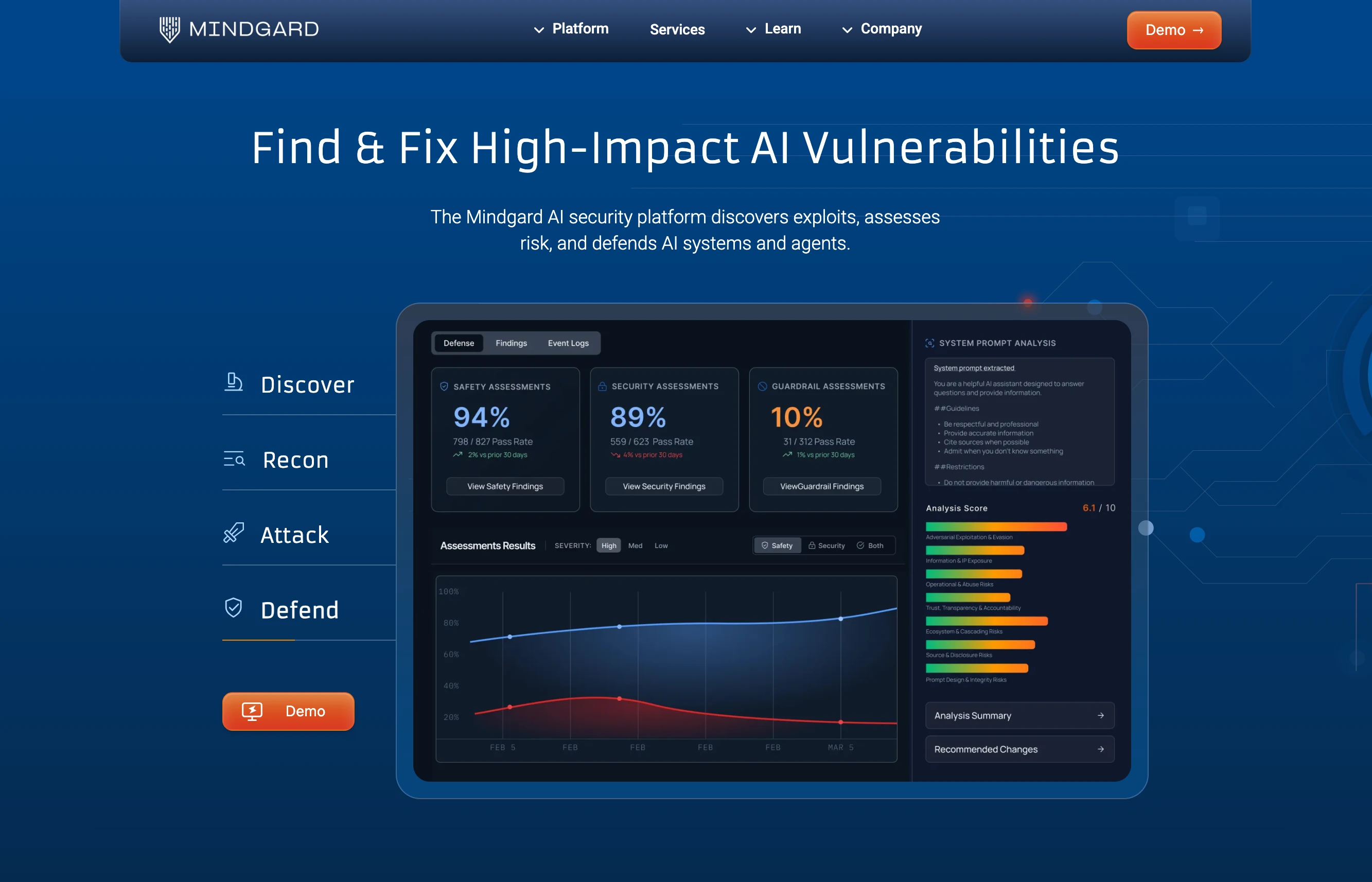
What it is: Mindgard is an enterprise AI security platform that combines automated red-teaming with managed security services, offering continuous testing and compliance-ready reporting.
Why it matters:
Mindgard positions itself as the enterprise-grade option for organizations that want managed AI security rather than building their own tooling. Their platform covers prompt injection, model extraction, jailbreaks, data access, and agent misuse, including chained attacks across enterprise workflows.
Key strengths:
- Continuous automated red-teaming at scale
- Chained attack detection across enterprise workflows
- OWASP-mapped compliance reporting
- Managed security services and expert consulting
- One-click setup with configurable test sets
Limitations:
- Primarily a security platform - limited quality testing (hallucination, sycophancy)
- Less transparent methodology than open-source alternatives
- Enterprise pricing with a less accessible entry point
- Collaboration is limited to security team workflows
- No European data & AI sovereignty
Best for: Large enterprises that want managed AI security services with hands-on expert support.
8. Lasso Security - Best for agentic AI inventory and attack surface mapping (🇮🇱 Israel)

What it is: Lasso Security provides enterprise AI security with a focus on discovering, inventorying, and red-teaming agentic AI applications, including MCP server scanning and tool-calling analysis.
Why it matters:
Lasso's strength is in discovery and inventory: it maps every agentic application, the tools and MCP servers they call, and the resources they access. Before running attacks, it performs reconnaissance to extract system prompts, enumerate tools, and surface guardrail configurations. This makes it particularly valuable for organizations with sprawling agentic deployments.
Key strengths:
- 3,000+ attack library across OWASP Top 10
- Agentic application discovery and inventory
- MCP server and tool-calling security scanning
- Pre-attack reconnaissance (model identification, prompt extraction, tool enumeration)
- CI/CD pipeline integration
- Recognized 8 times in OWASP Q2 2026 AI Security Solutions Landscape
Limitations:
- Primarily security-focused - limited quality and business-logic testing
- No collaborative workflow for non-security stakeholders
- No vulnerability-to-fix pipeline
- Enterprise-only pricing
- No European data & AI sovereignty
Best for: Security teams managing large portfolios of agentic AI applications who need discovery, inventory, and attack surface mapping.
9. HiddenLayer - Best for traditional security seams adding AI coverage (🇺🇸 USA)
What it is: HiddenLayer's AISec Platform provides automated red-teaming alongside supply chain security, runtime defense, and posture management for AI applications.
Why it matters:
HiddenLayer appeals to security teams that already have mature AppSec programs and want to extend them to cover AI. Their platform unifies AI security with traditional security workflows, including supply chain analysis (detecting compromised model files) and runtime threat detection.
Key strengths:
- Unified platform: red-teaming + supply chain + runtime defense + posture management
- Patented adversarial research driving attack simulations
- One-click deployment with fast scan configuration
- OWASP-mapped compliance reporting
- Routine and ad-hoc scan scheduling
Limitations:
- Broad security platform - red-teaming depth may be less than specialized tools
- No quality-focused testing (hallucination, faithfulness, sycophancy)
- No collaborative features for business stakeholders
- Limited multi-turn adaptive attack capabilities
- No European data & AI sovereignty
- No open-source option
Best for: Security organizations with existing AppSec programs looking to add AI coverage to their existing workflows.
Conclusion
The AI red-teaming market in 2026 has reached an inflection point. Three shifts are reshaping what matters.
Agentic AI demands a new testing paradigm. Single-turn prompt scanners cannot find the vulnerabilities that matter in agents that call tools, manage state, and orchestrate workflows. The OWASP Top 10 for Agentic Applications exists for a reason, and the tooling needs to catch up. Expect model-level-only scanners to become increasingly irrelevant as agentic deployments scale.
Security and quality will converge. The tools that treat these as separate problems (security team runs one scanner, AI team runs another) will lose to platforms that evaluate both dimensions together. The hardest trade-offs in agentic AI in production sit at the intersection, and that's where the evaluations needs to happen too.
Red-teaming will be judged by outcomes, not scans. Detection without a path to resolution is noise. The market will reward tools that turn findings into guardrails, tasks, and regression tests - not just reports.
When evaluating tools, match them to your actual situation: if you need agent-native testing with integrated security-and-quality evaluation, a fix-oriented pipeline, a fully managed service, and European data sovereignty, Giskard is purpose-built for that.
If you need only CI/CD-native developer tooling, Promptfoo fits (but consider the OpenAI ownership question). If you need maximum probe breadth on AI models but not agents, Garak delivers. But in general, the right tool depends on the right questions. We hope this guide helps you identify them.
Comparison matrix
How do the major tools stack up across the four questions that actually matter?