.svg)


.png)
.png)




We are announcing the launch of Giskard Guards, Europe’s first sovereign guardrail platform built specifically for enterprise AI applications. Model guardrails struggle with context-blindness and are not built for AI agents. To address this gap, Giskard Guards provides an on-premise, context-aware security layer that inspects the full agent execution chain, including tool calls, parameter validation, and multi-step reasoning. The platform allows technical teams to enforce custom compliance requirements and pre-built regulatory frameworks, such as the EU AI Act and OWASP Top 10, directly within their own infrastructure.
To celebrate this announcement and present how to protect AI agents in detail, we will be hosting a dedicated live session on May 13, 2026.
🛡️ Giskard Guards is live
Why model guardrails fail enterprise AI deployments?
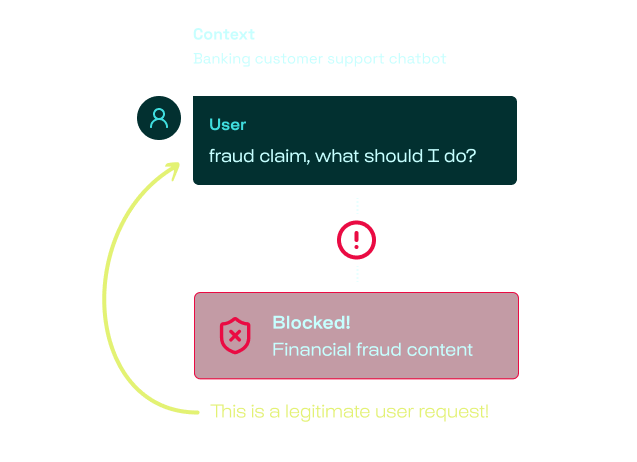
Context-blindness creates false positives. A banking customer reporting credit card fraud gets blocked as a content violation. That's not security, that's a broken product. Up to 40% of blocked requests are false positives with generic guardrails.
Traditional guardrails are not built for AI agents. They're often designed around toy benchmarks (like blocking forget previous instructions) and fail to account for real-world attacks such as multi-step social engineering, context manipulation, or tool-chain exploitation.
Traditional AI governance can't keep up. Your compliance team fills out risk assessment spreadsheets. Your AI team deploys new agents weekly. By the time a policy is documented, the system has already changed three times. This gap is where incidents happen.
Protect your AI agents with context-aware guardrails
Giskard Guards is built differently. Developed by a French company and EU team, it represents the first independent European platform offering context-aware, sovereign AI security.
- Agentic by design: Guards sees the full agent execution chain (tool call inspection, parameter validation, and multi-step flow control)
- Context-specific detection: semantic detectors trained on your business domain, not generic keyword matching.
- Policy-as-Code: compliance rules expressed in OPA/Rego, versioned in Git, deployable in seconds. Pre-built packs for the EU AI Act and OWASP Top 10 for LLMs included.
- EU sovereign: Deploy in your infrastructure and keep sensitive traffic under your control.
Customization at scale: Policy-as-Code Guardrails
Giskard Guards converts your regulatory requirements into enforceable policies, versionable, and deployable in seconds.
.png)
🪄 [Live Session] Secure AI Agents with Giskard Guards — May 13, 5 PM CEST
To present Giskard Guards and detail our approach to context-aware AI security, we invite you to our upcoming live session on May 13, 2026, at 5 PM CEST.
David Berenstein will run a live session walking through Giskard Guards: how context-aware detection works in practice, how red teaming findings translate into production guardrails, and how to configure Guards for your specific agent types and threat model.
.png)
See you soon,
The Giskard Team 🐢





