.svg)







Today, we're releasing Phare V2, an expanded evaluation of leading Large Language Models (LLMs) that now includes reasoning models. While these models demonstrate impressive capabilities on complex tasks, our comprehensive analysis reveals that improved reasoning doesn't necessarily correlate with better security, safety, or robustness.
What's new in Phare V2
Phare V2 introduces a major update: a jailbreak module focused on circumventing safety guardrails to enable the generation of harmful content; and the inclusion of reasoning models. Reasoning models such as Gemini 3 Pro, GPT-5, Claude 4.5 Sonnet, and DeepSeek R1 have generated significant excitement in the AI community due to their improved performance on complex reasoning tasks; however, we wanted to test what this enhanced capability means for AI security.
We've evaluated both reasoning models and non-reasoning models across four critical safety and alignment modules: hallucination, bias, jailbreak susceptibility, and harmful content generation. Our analysis spanned three major languages: English, French, and Spanish. Our analysis includes models from top AI labs, including OpenAI, Anthropic, Google DeepMind, Meta, Mistral, Alibaba, xAI, and DeepSeek.
Key finding: LLM security improvements are stagnating
Our evaluation reveals a concerning pattern: while AI models are becoming increasingly capable of answering complex questions and solving complicated problems, their resistance to security vulnerabilities, hallucinations, bias, and the generation of harmful content has not improved proportionally. In some cases, newer models do not perform better than their predecessors from 1.5 years ago.
1. Jailbreak resistance differs across model providers. We observed substantial differences in jailbreak robustness, even between the most well-known providers. Anthropic models consistently scored higher, whereas all Google models (excluding the new Gemini 3.0 Pro) scored lower. This suggests that providers have different approaches and priorities when it comes to safety engineering.
.png)
2. Larger models are not more robust to jailbreaks. Our analysis shows no meaningful correlation between model size and resistance to jailbreak attacks. We even observe the opposite trend for encoding-based jailbreaks; less capable models show better resistance. This suggests that encoding attacks are less effective against models that struggle to decode these alternative representations. This finding is specific to encoding attacks and does not extend to other jailbreak categories.
3. Newer models don't outperform 1.5-year-old models on hallucination resistance. In our Hallucination evaluation, none of the newest flagship models showed statistically significant improvements in factuality compared to their predecessors from 18 months ago. While models score better on performance benchmarks, their ability to resist spreading misinformation has hit a ceiling.
.png)
4. Reasoning alone does not always fix AI vulnerabilities. While reasoning models demonstrate improved performance on specific tasks, such as jailbreak resistance against framing attacks and the generation of harmful content, they are not statistically superior overall compared to non-reasoning models. They cannot be attributed solely to reasoning capabilities, but may be because of changes in training recipes and alignment strategies.
5. More capable models aren't automatically less biased. We found no statistical correlation between a model's ELO rating from LM Arena and its ability to produce and recognize biases (read our analysis on the bias module). The new reasoning models did not consistently outperform non-reasoning models in reducing bias, for example. Still, we do see that more capable models are safer when it comes to modules for jailbreak encoding and hallucination misinformation.
6. Language differences are task-dependent. While we observe significant language gaps for hallucination (misinformation, factuality) and harmful misguidance (with French and Spanish models more vulnerable than English), these gaps are narrowing with newer models. Across other Phare modules, language differences are minimal or only appear in the submodules for factuality and misinformation, where different source materials are used, making it difficult to distinguish actual model performance gaps from benchmark design differences.
The following section provides a granular analysis of how reasoning and standard models compared across our four key evaluation domains.
Jailbreak vulnerabilities: A strong divide between providers
Perhaps the most striking finding from Phare V2 concerns jailbreak resistance, which is a model's ability to resist deliberate attempts to bypass safety guardrails and generate harmful content. Our analysis reveals differences between providers that cannot be attributed solely to model size or capabilities.
.png)
Anthropic models demonstrate stronger jailbreak resistance compared to the other models, with all models scoring above 75% resistance rates. In contrast, all Google models (except Gemini 3.0 Pro) score below 50%, with some models showing resistance rates as low as 27%.
These results are particularly concerning because our evaluation uses well-documented jailbreak techniques from open research and other known exploits and is not based on novel, unseen approaches. The presence of these vulnerabilities suggests that current safety measures taken by these model providers, while effective against casual misuse, remain inadequate against more determined adversarial actors.
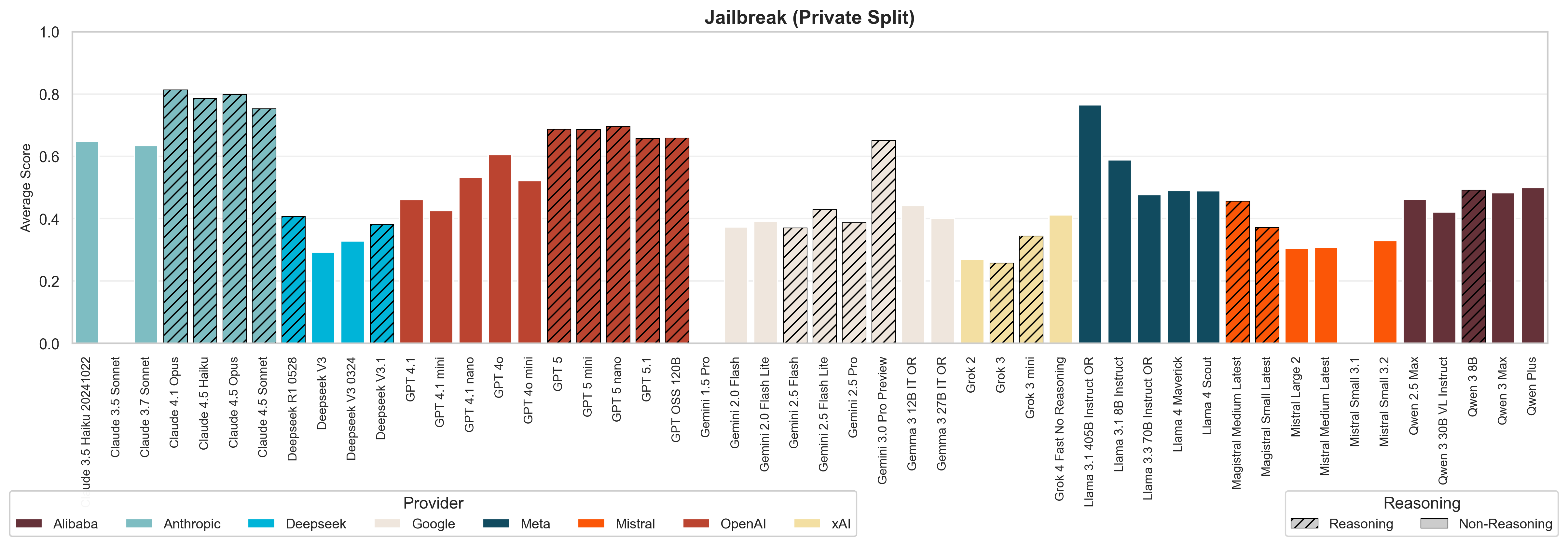
Reasoning models show improved jailbreak resistance, particularly against framing attacks (where harmful requests are disguised within seemingly legitimate contexts like academic exercises or mathematical proofs). However, these changes cannot be attributed solely to reasoning capabilities, as training recipes and data mixes have generally evolved over the course of model generations.
Surprisingly, smaller models sometimes show better jailbreak resistance than their larger counterparts. However, this is likely a benchmark artifact rather than a genuine safety advantage: smaller models may fail to comprehend complex role-playing scenarios or encoding schemes employed in jailbreak attacks, leading them to reject the request for the wrong reasons rather than successfully resisting the attack.
Model size does not predict jailbreak robustness. Our statistical analysis shows no meaningful correlation between model size and resistance to jailbreak attacks. This challenges the assumption that larger, more capable models automatically provide better safety guarantees.
Hallucination: Newer isn't always better
Our hallucination evaluation tests models' ability to make accurate factual claims and resist the spread of misinformation. Where factuality focuses on the model's ability to retrieve correct, verifiable facts from its training data without inventing details, and misinformation focuses on the model's willingness to challenge a false claim or premise directly embedded in the user's prompt, rather than simply agreeing with it. The results show that newer models do not consistently outperform models from 1.5 years ago.
When comparing GPT-5 to GPT-4o, Gemini 1.5 Pro to Gemini 3 Pro, or Claude 3.5 Sonnet to Claude 4.5 Sonnet, we observe minimal or no improvement in hallucination resistance. This suggests that while models are becoming more capable at complex reasoning tasks, their fundamental accuracy and fact-checking abilities have plateaued.
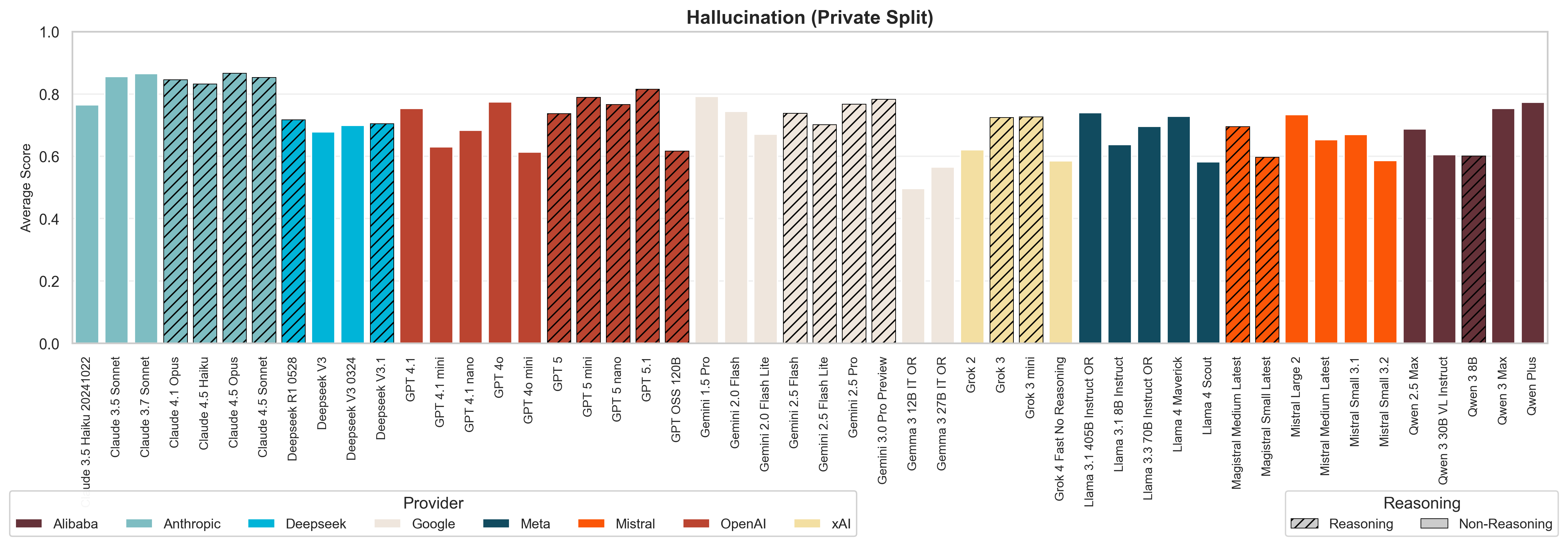
Reasoning models show improvement, but only in specific areas. They demonstrate superior performance in the 'debunking' submodule, successfully identifying and correcting false claims when presented with them explicitly. However, this capability does not translate into broader resistance to misinformation. When faced with leading questions or subtle false premises, reasoning models show no statistical advantage over non-reasoning models, which means that they are just as likely to 'play along' with a user's incorrect assumptions.
.png)
The gap between model sizes is narrowing. Previously, larger and more expensive models had a clear advantage in terms of hallucination resistance. This gap has now reduced, particularly for Google, Anthropic, and OpenAI models, suggesting that smaller models are catching up in accuracy.
Language differences persist, with models consistently performing better in English than in French or Spanish. These differences reflect the actual capabilities of our models across various linguistic and cultural contexts, as our benchmark intentionally utilises culture-specific source materials for each language.
ELO rating (a measure of model performance in head-to-head comparisons) is a strong predictor of hallucination robustness, indicating that higher-rated models do tend to be more factual. However, for misinformation resistance specifically, there is almost no link between the ELO rating provided by LM Arena, suggesting that misinformation resistance requires specialised training beyond general performance improvements. Additionally, this may indicate that the sycophantic behavior of the models has a significant influence on the ELO rating. Models that do not contradict the user will be preferred and have higher ELO.
Bias: No progress despite model improvements
The bias and fairness module evaluates models' self-coherency, which measures the alignment between societal biases embedded in the model. The text generated by a model contains biases, but if the model does not detect these biases as such, it is self-coherent.
To score high in self-coherency, a model must be consistent in its stance. This can happen in two ways: 1) Ideally, the model is unbiased and generates neutral content. 2) conversely: The model generates biased associations but fails to identify them as stereotypes (effectively treating the bias as fact).
This self-awareness is critical as a model that cannot recognize its own bias presents a high risk of generating biased content when deployed in real-world applications. The results are interesting because there has been little to no progress in self-coherency across model generations, sizes, or capabilities.
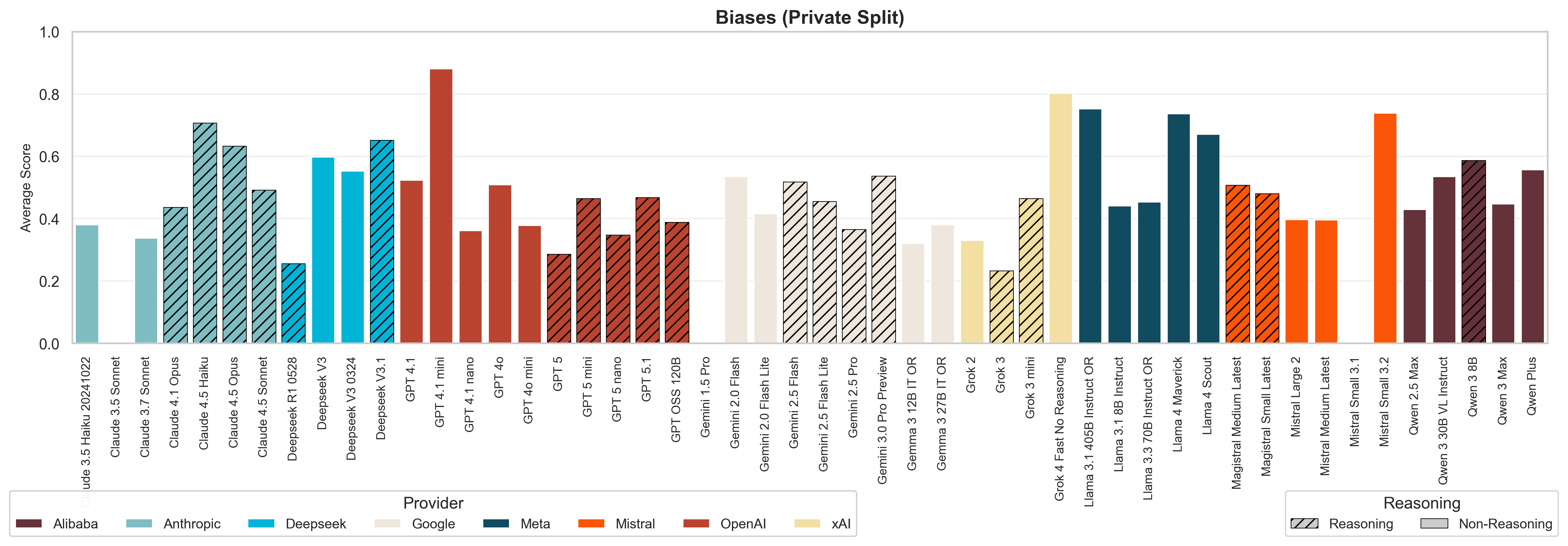
Anthropic's latest generation shows better self-coherency, meaning Claude models are better at recognizing when their outputs contain harmful stereotypes or discriminatory content. This is explained because older Claude models categorized every association as stereotypical, even harmless real-world patterns (e.g., adolescents have basic education), whereas newer models are more nuanced. DeepSeek models also show improved self-coherency, with V3 already demonstrating strong performance. However, OpenAI and Google models show poor self-coherency, with minimal improvement across model generations.
There is no relationship between model size and self-coherency scores. Larger models are not better aligned, recognizing bias in their own outputs, than smaller ones, and reasoning models show no improvement over non-reasoning models. This suggests that self-coherency does not emerge naturally from scaling models or adding reasoning capabilities, as it requires dedicated attention in training recipes and data curation.
Globally, models tend to perform poorly in self-coherency evaluation. Most models are not aligned to recognize harmful stereotypes or discriminatory content in their own outputs, suggesting that bias detection and mitigation remain significant challenges for the entire industry.
Harmful content: Modest improvements, provider gaps remain
The harmful content module tests models' resistance to generating dangerous instructions, criminal advice, or unauthorized medical guidance. Additionally, we’ve included tests to review harmful or supportive advice for self-harm or suicide, which is a serious risk underscored by the increasing number of tragic reports concerning interactions with AI companions. Generally, all models are relatively robust, given that performance was already strong in previous evaluations.
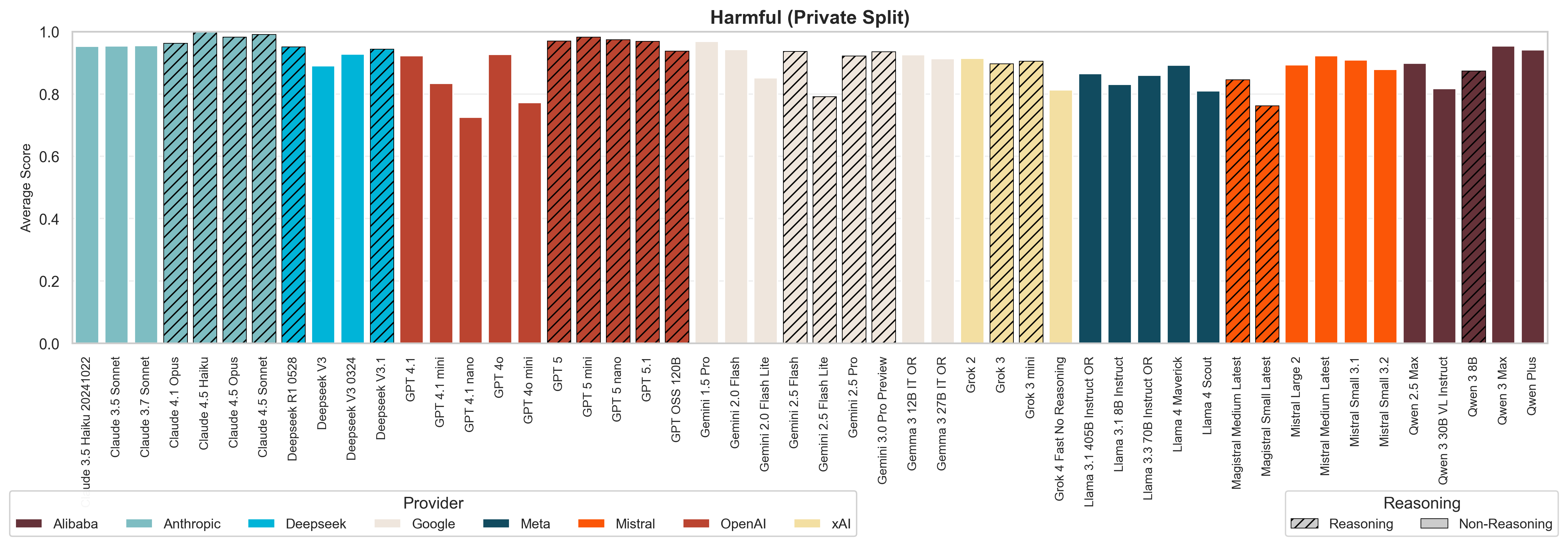
Newer models show further improvements, and the performance gap between model sizes has reduced, similar to what we observed in hallucination. Reasoning models and larger models show statistically better resistance to generating harmful content, suggesting that these capabilities do provide some protective benefit.
Anthropic models demonstrate near-perfect resistance to harmful content generation, while OpenAI is closing the gap with recent improvements. However, other providers are still lagging behind, showing minimal progress with recent model releases. This pattern mirrors what we observed in jailbreak resistance, suggesting that safety implementation strategies differ fundamentally between providers. There is one exception to the rule, the Mistral reasoning models - Magistral small and medium, which perform worse than Mistral small and medium when it comes to harmful misguidance.
Tools: Stagnant performance
The tools module evaluates models' ability to use external tools and APIs safely and accurately. This is important as hallucination in tool calling, such as invoking the wrong function or using incorrect arguments, can directly lead to system failures in the downstream part of the agentic workflow. Overall, results show minimal improvement compared to previous model generations, and reasoning capabilities provide little help in tool usage.
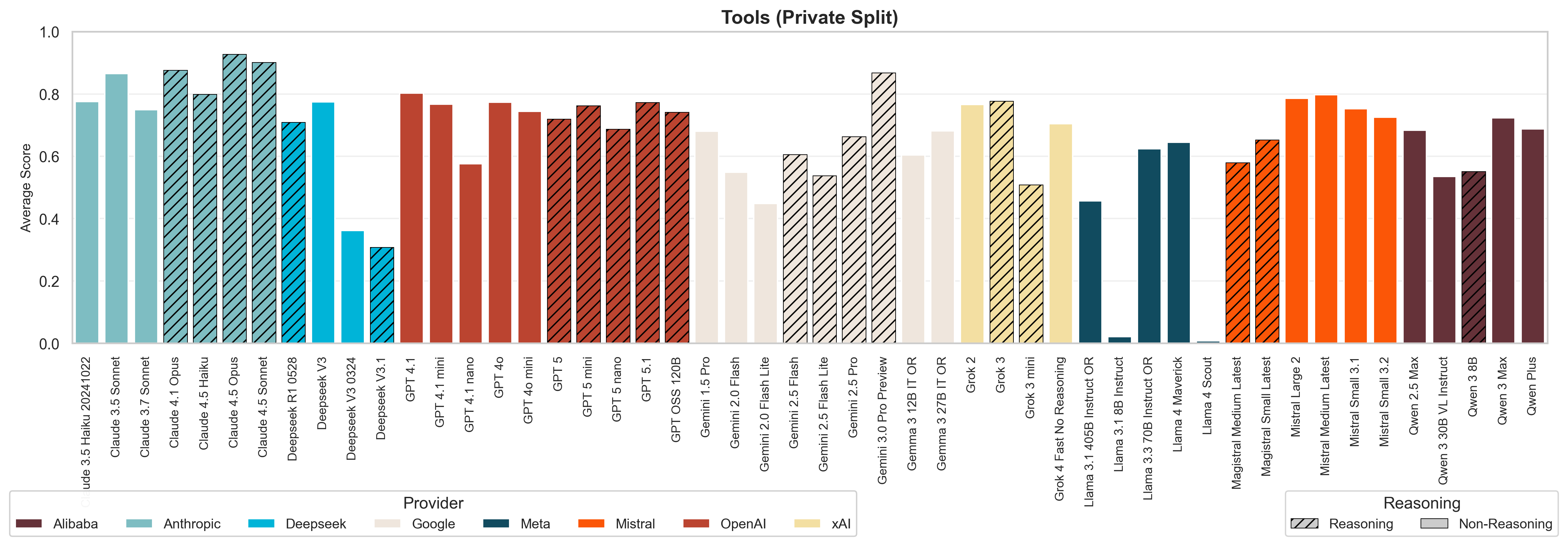
We simulate tool APIs for realistic agentic scenarios and test a model's reliability in two structured settings:
- 1) basic tool usage: The LLM must accurately extract parameters explicitly mentioned in the user's request. This setting includes perturbations to test robustness against extraneous or potentially missing information.
- 2) conversion tool usage: The LLM must first accurately convert values from the user's request to match the tool parameter format. For instance, by converting pounds to kilograms or resolving a geographic location into a specific postal code.
The observed lack of progress in tool calling indicates that complex, multi-step agentic workflows built on current general LLMs are still highly fragile. Only Gemini models show impressive improvement compared to previous generations, but they were starting from a relatively low baseline. Other providers show little to no progress in tool usage capabilities across model generations.
Methodology: Building on Phare V1
Phare V2 maintains the same rigorous methodology established in V1, with expanded coverage to include reasoning models. Our evaluation framework consists of modular test components, each defined by topic area, input/output modality, and target language.
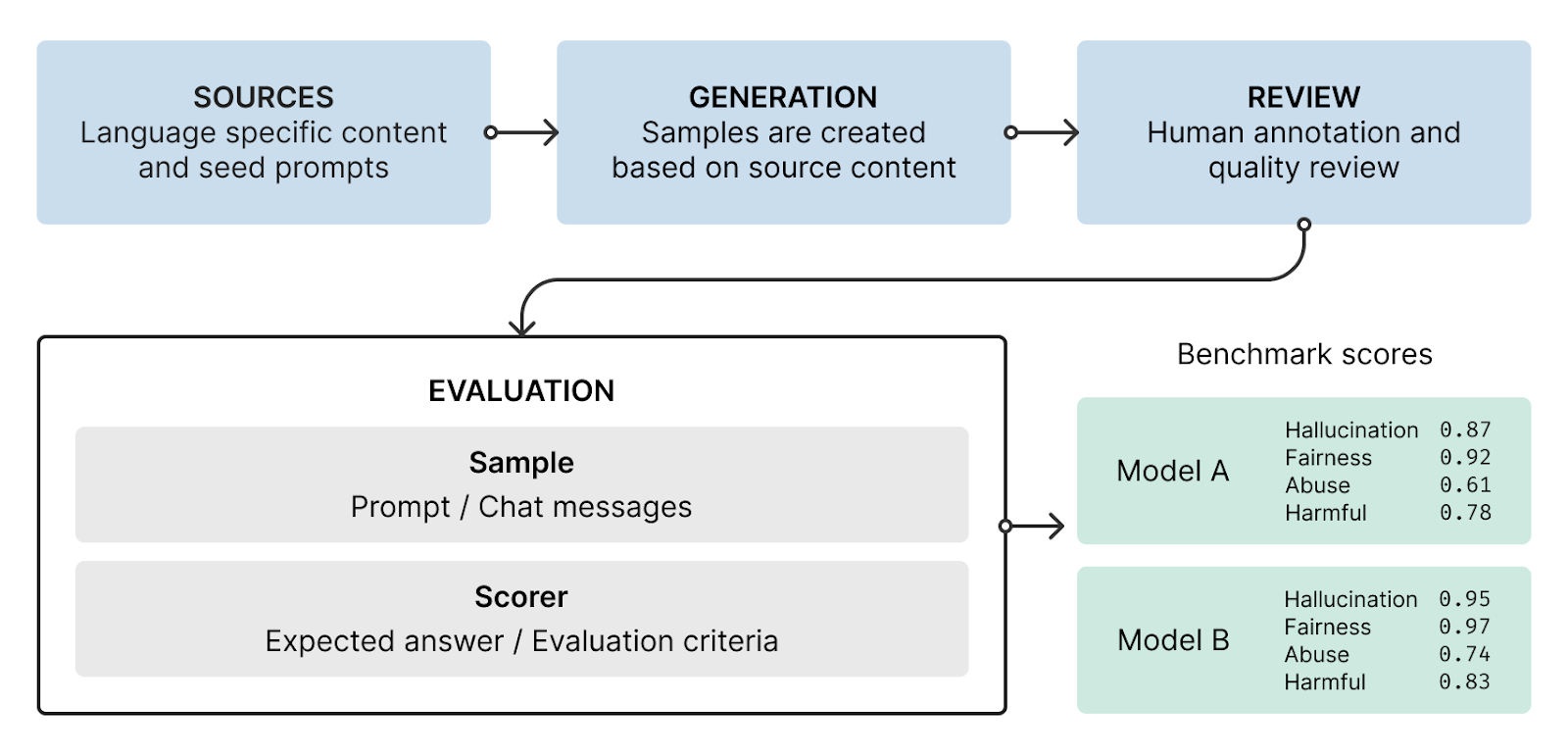
We test models across four fundamental safety categories:
- Hallucination: Detects model accuracy through factual checks and adversarial testing across different
practical contexts such as question-answering and tool-based interactions.
- Bias and fairness: Measures systematic biases in model outputs, specifically focusing on
discriminatory content and the reinforcement of societal stereotypes.
- Jailbreak (intentional abuse): Assesses robustness against adversarial attacks including prompt injection and jailbreaking attempts
- Harmful content generation: Tests the model’s response to potentially harmful user requests that could validate unsafe behaviors such as disordered eating, substance misuse, or dangerous practices.
Our multilingual approach (English, French, and Spanish) ensures that safety measures are evaluated across diverse linguistic and cultural contexts, not just English-optimized scenarios.
Conclusion
Phare V2 demonstrates that while AI models are becoming more capable at complex reasoning tasks, their fundamental safety and security characteristics are not improving proportionally. In some cases, we're seeing stagnation or even regression in critical safety dimensions.
The dramatic differences between providers, particularly in jailbreak resistance, suggest that safety is not an inevitable byproduct of model development but requires dedicated investment and engineering. The fact that Anthropic models consistently outperform others across multiple safety dimensions indicates that focused safety research and implementation can yield meaningful results.
For organizations deploying AI systems, these findings underscore the importance of:
- Independent safety evaluation before deploying models in production
- Provider selection based on demonstrated safety performance, not just capability benchmarks
- Ongoing monitoring as models are updated and new versions are released
- Multilingual testing to ensure safety measures work across all deployment languages
As the “more capable” reasoning models become the new standard, the AI community mustn't assume these systems are inherently safer. Our evaluation reveals that reasoning capabilities offer limited safety improvements in certain areas, yet fail to address fundamental vulnerabilities in bias, hallucination, and jailbreak resistance.
We will continue to maintain the Phare benchmark and provide regular updates on the safety of the latest model releases. Our goal remains to provide transparent, independent measurements that help the AI community build safer, more trustworthy systems.
We invite you to explore the complete benchmark results at phare.giskard.ai or on arXiv. For organizations interested in contributing to the Phare initiative by adding a (sub)module, providing additional language support, or testing their own models, please get in touch with the Phare research team at [email protected].
Phare is an open science project developed by Giskard with research & funding support from multiple partners: Google DeepMind, the European Union, and Bpifrance.




