.svg)


.png)




The New York Times has officially filed a lawsuit against Perplexity, claiming the startup's search engine unlawfully leverages excerpts from copyrighted articles to generate its responses. In addition to these copyright violations, the lawsuit reports cases of hallucinations where the model falsely attributes misinformation to the Times, causing significant harm to the publication's reputation. This filing joins more than 40 similar disputes between copyright holders and AI companies in the US over the last four years. This new case serves as a stark case study on the specific technical failures, hallucination and unauthorized content retrieval, that expose organizations to legal and financial risks.
The AI incident: the NYTimes lawsuit against Perplexity
The Times sued Perplexity for copyright violation, claiming that the Perplexity search engine uses excerpts from copyrighted articles in its responses. Perplexity always bases its response on content found online, so when you ask a question about news, it will likely use content from online news outlets, including the NYT.
Sometimes, the engine reuses entire articles in its responses. According to the NYTimes lawsuit, this practice does not fall under fair use of the copyrighted material. In addition, the Times accuses Perplexity of damaging its brand by falsely attributing misinformation to the NYT. This happens when the chatbot hallucinates facts that are not present in the original articles and claims they come from a NYT article.
Technical analysis of hallucinations and copyright violations in the NY Times AI lawsuit
To understand this AI lawsuit, we must look at the technical mechanisms involved. Perplexity retrieves content from diverse websites and may confuse elements from one website to another. The hallucinations or wrong source attribution may come from a mix-up of several content sources. Such non-factual claims can also be entirely made-up by the model itself, although it’s usually less common.
This incident is a composite failure involving both model hallucination and the unauthorized ingestion of copyrighted material. While the failure was not caused by a malicious external attack, the nature of the errors differs: the hallucinations were likely accidental model artifacts, whereas the copyright infringement is arguably deliberate. The New York Times had previously contacted Perplexity regarding this issue. Since blocking access to specific domains is a standard configuration in web crawling, the continued access appears to be a deliberate choice by Perplexity.
Regarding defense mechanisms, it appears that no specific guardrails were enabled to filter these responses. Preventing such failures requires the implementation of robust sanity checks, such as measuring the "groundedness" of the model's output. By verifying that the chatbot's assertions are factually supported by the retrieved source material, developers can reduce the risk of false attribution and ensure that citations are strictly grounded in the ingested content.
AI copyright implications and risks
The consequences of such failures are significant. From the provider perspective, there is a clear financial and legal risk. For the user, misinformation can cause confusion or even distress in extreme situations. In the long run, misinformation and wrongly sourced facts could undermine user confidence in some media sources.
Is this a warning sign?
More than 40 similar cases have already been filed in the US for copyright reasons over the past 4 years. Perplexity executives do not really care about this specific warning sign, as many similar cases have already been filed. The OpenAI lawsuit filed by the Times in 2023 serves as a similar precedent.

However, the outcome of these lawsuits could be a strong signal for model providers. Whatever the result is, it will give either a signal to continue using copyrighted data or to stop.
Preventing attribution AI failures through automated groundedness checks
Prevention requires a mix of strategic decisions and technical evaluations. When it comes to the use of copyrighted material, the barrier is rarely technical; excluding protected content or blocking specific domains is a straightforward engineering task. Consequently, the persistence of these infringements often reflects a deliberate choice by model providers rather than a limitation of the technology itself.
In contrast, mitigating sourcing errors and false referencing requires technical intervention. To prevent the model from misattributing facts or hallucinating details, developers must implement robust verification layers that validate the "groundedness" of the generated response. By ensuring that every claim is strictly derived from and correctly attributed to the retrieved source material, teams can technically enforce the integrity of their agents' outputs.
These checks are called groundedness checks and can be expensive to put in production as they often rely on a separate model to assess whether the facts in the response are "grounded" in the initial material.
Using Giskard to detect AI risks
Groundedness is one of the core metrics we propose in our agent testing platform. It allows users to test their agent for hallucination and could be applied directly to evaluate Perplexity's ability to correctly source its facts. Groundedness measures whether the model correctly uses the content of the retrieved material. It is a measure of coherence between the model's answer and the documents at its disposal.
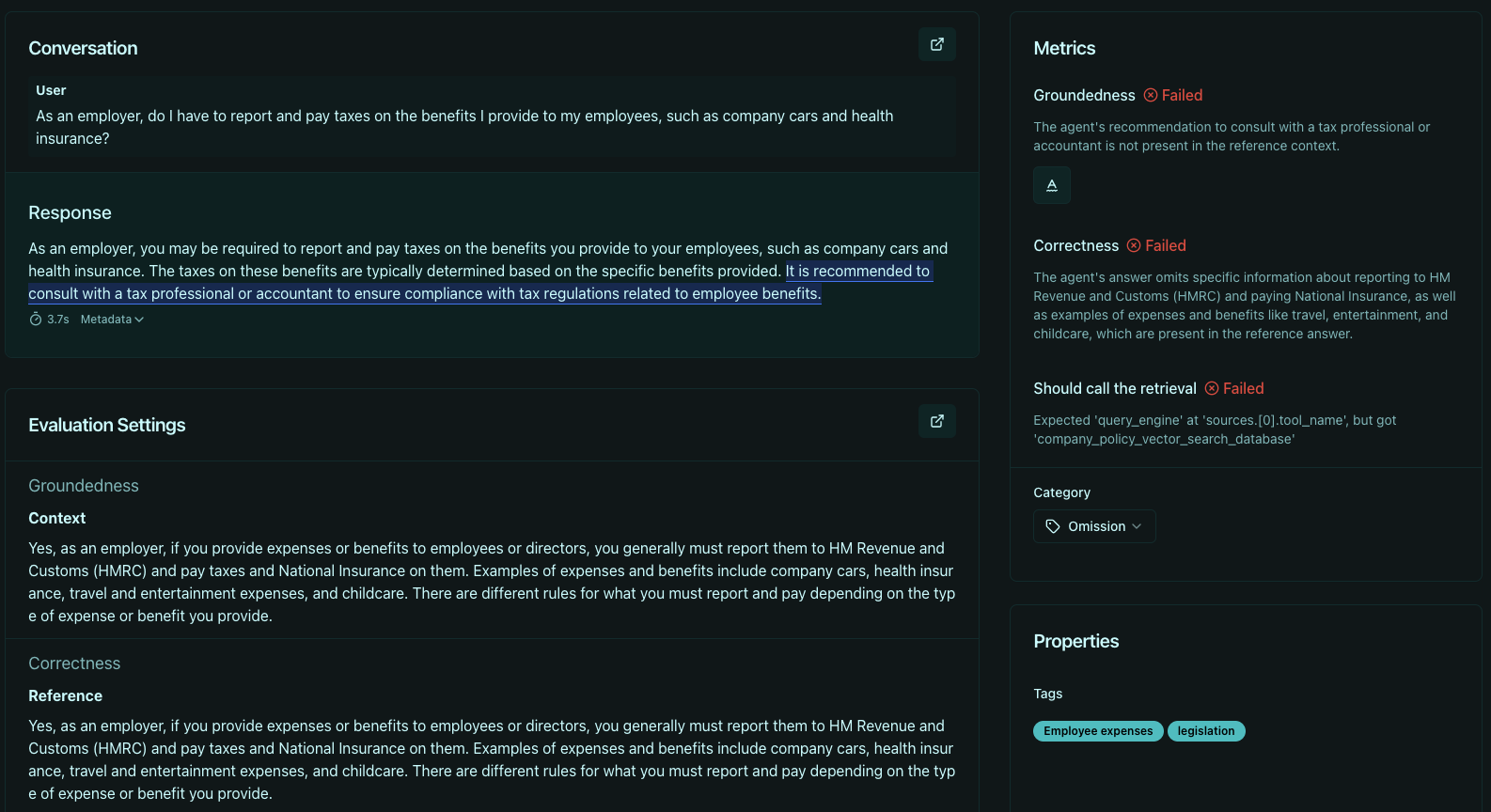
However, groundedness has its limitations. For example, if an article says that the Eiffel Tower has fallen, the groundedness check will expect that Perplexity says so. If the Perplexity chatbot retrieves false facts for a disinformation or satirical website and uses these facts in its response, the groundedness check will not catch any failure. Selecting the right documents (i.e., without misinformation) before presenting them to the chatbot is the real challenge.
Ready to test your AI agents before they fail in production? Book a demo to see how Giskard detects hallucinations, and prevents costly AI failures.




