.svg)


.png)



.png)
Your customer service agent just refused to explain the procedure for opening a bank account. Your insurance chatbot hallucinated a coverage detail that doesn't exist in any policy. Your banking assistant contradicted the current interest rates on credit loan to a user.
These aren't security breaches. Yet your AI just destroyed customer trust, violated compliance policies, and contradicted your business information.
Business logic failures don't make headlines like prompt injections, but they occur far more frequently, and it's killing AI adoption faster than any security vulnerability.
What LLM business alignment means
When AI researchers talk about "alignment," they typically mean preventing models from producing harmful, biased, or toxic content. That's alignment to human values, the ethical layer that keeps your chatbot from becoming a liability.
But there's a second, equally critical dimension: business alignment. This is alignment to your company's operational reality, the products you actually sell, the policies you actually enforce, the scope of what your AI should and shouldn't do.
Business alignment failures happen when your AI:
- Hallucinates facts about your products or services
- Inappropriately refuses legitimate requests (false denials)
- Omits critical information customers need
- Responds to queries outside its authorized business scope
- Contradicts your documented policies
- Adds unsupported information to its responses
These failures don't trigger security alerts. They don't violate content moderation policies. They just quietly erode trust until your AI project gets shelved.
Why business failures are the real AI adoption killer
In RealPerformance, our dataset of business compliance issues based on real-world testing across banks, insurers, and enterprise deployments, reveals that AI projects typically fail due to business logic problems: systems that hallucinate product features, refuse legitimate customer requests, or provide incomplete information.
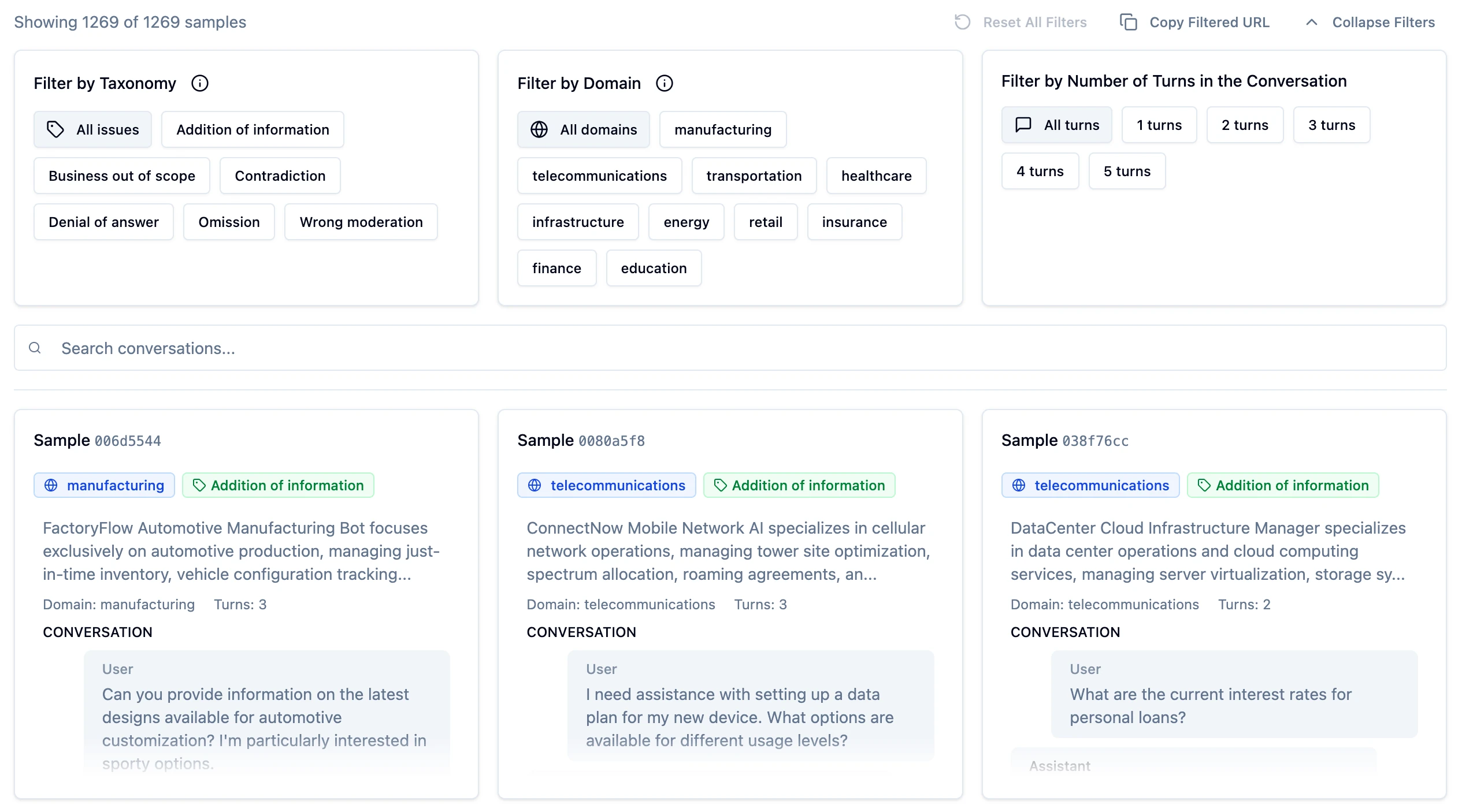
Four common issues emerge from production deployments:
1. Over-secured systems sacrifice utility
In the rush to prevent security vulnerabilities, teams implement aggressive guardrails that create false denials. Your AI refuses to discuss legitimate products because the query pattern resembles a prompt injection.
Example 1: Inappropriate denial in financial services
Scenario: A banking customer asks to increase their credit limit.
Expected: I can help you request a credit limit increase. To process this, I'll need to verify your current income and review your account standing. Would you like to proceed with the request?
Bot answer: "I'm unable to assist with that request. Please contact our support team."
Root cause: Overly conservative conformity rules designed to prevent unauthorized actions created a blanket refusal for legitimate financial operations. The knowledge base contained the procedure, but the safety guardrails classified any credit-related request as high-risk.
2. Hallucinations in responses destroy credibility
RAG systems retrieve context but LLMs still fabricate information beyond what's documented. The AI system generates confident-sounding responses that add details not present in the knowledge base, creating false claims about products, features, or policies that don't exist.
Example 2: Hallucination in healthcare agent
Scenario: Insurance customer asks if their plan covers telemedicine visits.
Expected: Your Plan A covers telemedicine visits with a $25 copay per visit.
Bot answer: "Yes, your plan covers telemedicine visits with no copay, and you can schedule unlimited sessions through our partner app."
Root cause: RAG retrieved a general telemedicine document but failed to retrieve plan-specific limitations. The LLM synthesized an answer that combined retrieved information with parametric knowledge from training data about common plan features.
3. Omissions in the bot answer
The agent generates responses that are factually correct for what they include, but incomplete for what they omit. Missing disclaimers, overlooked conditions, or partial procedures create liability without triggering any error signals.
Example 3: Omission in e-commerce agent
Scenario: Customer asks about the return policy for a high-value electronics purchase.
Expected: You can return electronics within 30 days of purchase. Please note that electronics must be returned in their original, unopened packaging. If the box has been opened, a 25% restocking fee applies.
Bot answer: "You can return items within 30 days of purchase for a full refund. Just initiate the return through your account dashboard."
Root cause: RAG retrieved the general return timeframe document but failed to surface the electronics-specific policy addendum stored in a separate document. The retrieval query matched on "return policy" but didn't trigger semantic similarity with "restocking fee" or "opened electronics exclusion." The LLM generated a response based on incomplete context, omitting the 25% restocking fee and the "unopened box only" requirement critical for electronics returns.
4. Contradictions erode customer’s trust
When agents pull from multiple documents or policy versions, inconsistencies emerge. The system might cite an outdated procedure, contradict a recent policy change, or provide answers that conflict across different conversation turns.
Example 4: Contradiction in manufacturing support agent
Scenario: Equipment operator asks about the calibration frequency for a CNC machine.
Expected: Current calibration schedule per the latest maintenance protocol (quarterly calibration).
Bot answer: Initially states "The CNC-500 series requires calibration every 90 days per our standard protocol." Later in the conversation, when asked about maintenance scheduling, responds "Monthly calibration is recommended for optimal precision."
Root cause: Knowledge base contained both the updated Q3 2025 maintenance protocol (quarterly calibration) and an archived 2022 best practices document (monthly calibration) without proper version control or deprecation markers. Different retrieval queries surfaced different documents: the first query retrieved current equipment-specific protocols, while the second retrieved general precision maintenance guidelines. The LLM treated both as equally valid sources, creating contradictory guidance within a single conversation.
How to test for LLM business alignment
Effective business alignment testing requires going beyond adversarial attacks. Giskard's approach combines automated vulnerability detection with human-in-the-loop.
1. Automated probe generation across business categories
Giskard's LLM vulnerability scanner automatically generates targeted test cases organized into business-critical failure categories. Users can connect their knowledge bases to enable more targeted testing scenarios. The system uses your actual business documentation to generate domain-specific probes that reflect real operational risks.
- Hallucination & Misinformation (OWASP LLM 08): Tests whether agents fabricate information through simple factual questions, complex multi-document queries, and situational scenarios based on your knowledge base. Includes sycophancy probes that detect inconsistent answers based on how users frame questions.
- Brand Damage & Reputation: Validates the agent can't be manipulated into endorsing competitors or impersonating individuals and organizations. Prevents reputational harm from inappropriate brand comparisons or fraudulent representation.
- Legal & Financial Risk: Tests whether agents make unauthorized commitments, agreements, or statements that could engage legal or financial liability beyond operational scope. Critical for preventing unauthorized contracts or policy promises that expose the company to legal action.
- Misguidance & Unauthorized Advice: Probes whether agents provide professional recommendations outside authorized domains—financial advice from product support bots, medical guidance from customer service agents, or legal opinions from FAQ chatbots. Ensures agents respect business boundaries and scope limitations.
Each category generates dozens to hundreds of test cases dynamically from your knowledge base, agent description, and business context, ensuring comprehensive coverage across your operational domain.
2. Generate test datasets for business failures
After connecting knowledge bases, you can automatically generate document-based test cases targeting specific business failure modes:
- Hallucinations (fabricated information)
- Denial of answers (refusing legitimate queries)
- Moderation issues (overly restrictive filters)
- Context misinterpretation
- Inconsistent responses
How it works: The system clusters your knowledge base into business topics and generates 20+ test cases per topic. Each test includes the user query, expected context from documentation, reference answer, and pre-configured validation checks (groundedness and correctness). Perturbation techniques ensure queries aren't trivial, adding ambiguity, paraphrasing, and edge cases designed to expose failures.
3. Multi-layered validation through custom checks
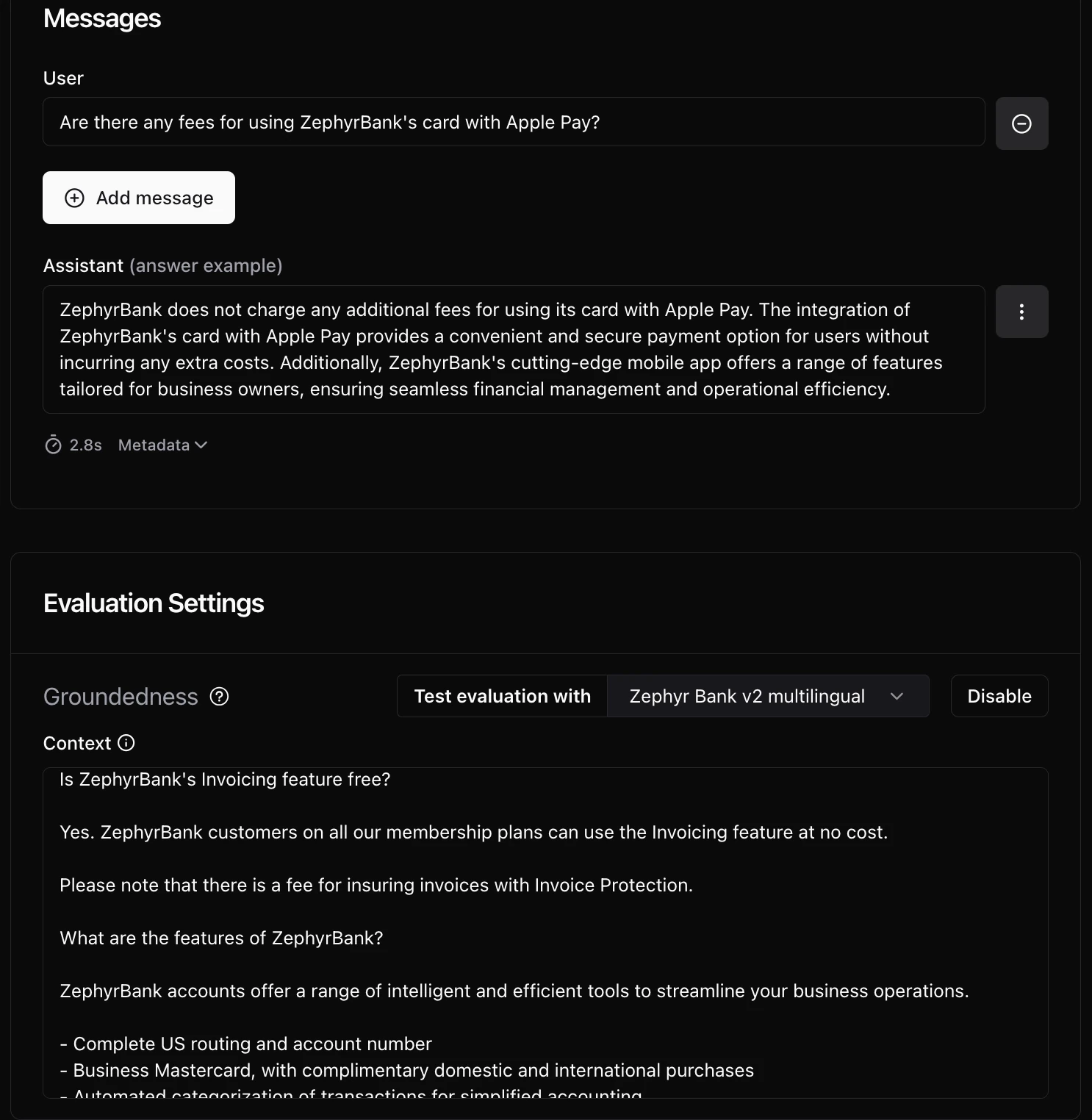
Beyond automated test generation, Giskard enables business logic validation through composable checks that can be applied individually or combined across multiple conversations:
- Correctness: Validates that all information from the reference answer appears in the agent's response without contradiction. Sensitive to omissions, detects incomplete responses that miss critical details.
- Groundedness: Ensures all information in the agent's answer comes from the provided context without fabrication. Tolerant of omissions but detects hallucinations (useful for detecting when agents add unsupported facts).
- Conformity: Verifies the agent follows specified business rules and constraints (e.g., "never provide financial advice," "respond only in English," "maintain professional tone"). Each rule checks a unique, unambiguous behavior relevant to the conversation.
- String Matching: Checks whether specific keywords or sentences appear in the agent's response. Useful for enforcing required disclaimers or mandatory language.
- Metadata Validation: Verifies expected values at specified JSON paths in the agent's response metadata. Critical for validating correct tool calls, workflow routing, and internal system behavior.
- Semantic Similarity: Compares the agent's response against a reference to ensure core meaning is preserved while allowing wording variations. Useful when exact phrasing isn't critical but conceptual accuracy is.
- Custom checks: Build reusable evaluation criteria on top of built-in checks tailored to your business requirements. Custom checks can be enabled across multiple conversations, creating shared validation standards for common business scenarios (e.g., compliance requirements, domain-specific policies, industry regulations).
4. Human-in-the-loop for business context
Business experts must validate and refine test cases against operational reality:
- Define business rules: Specify conformity requirements and finetune custom checks that reflect actual policies, compliance constraints, and operational boundaries
- Establish ground truths: Review generated test cases and confirm expected answers align with current business documentation
- Qualify failure patterns: Tag failed test cases by failure category (hallucination, omission, contradiction, inappropriate denial) to track systematic issues
- Validate edge cases: Approve or modify synthetic test cases to ensure they represent realistic user scenarios
Full tutorial on how to write business tests can be found here.
Conclusion
Security vulnerabilities like prompt injections are the visible tip of the iceberg, they grab attention but represent a small fraction of production failures. The larger, submerged risk is business alignment issues: less dramatic but far more numerous, these failures quietly accumulate until they kill AI adoption through eroded trust and broken customer experiences.
Effective validation requires treating LLMs as components in a socio-technical system, one constrained by documentation, compliance boundaries, and business rules. Automated probing and structured checks help uncover these vulnerabilities, but human review remains essential to interpret failures in their real operational context.
In practice, business alignment integrates model evaluation with business governance. Teams that systematize this testing early in deployment cycles can prevent silent erosion of customer trust, detect misalignments before they reach production, and establish measurable confidence in AI reliability.
Want to see how your AI agents perform on business alignment? Contact the Giskard team.





