.svg)






.png)
According to Anthropic, the Chinese state-sponsored group, designated GTG-1002, used Claude Code to autonomously conduct reconnaissance, exploit vulnerabilities, harvest credentials, and exfiltrate data across roughly 30 targeted organisations, with AI executing 80-90% of tactical operations independently.
However, security experts have raised concerns over the lack of public technical evidence, such as Indicators of Compromise (IoCs), questioning whether the activity represents true AI autonomy or simply advanced, scripted automation.
Still, as a company focused on AI security, we felt it was worthwhile to review the attack as well, to share our perspective and help spread awareness across our community. So, let’s dive a bit deeper into the attack.
How the cyberattack worked
The alleged campaign showcases what we call dynamic agentic attacks, which is the most advanced category in our attack taxonomy.
These agentic attacks relied on several features of AI models that did not exist, or were in much more nascent form, just a year ago:
- Intelligence. Models’ general levels of capability have increased to the point that they can follow complex instructions and understand context in ways that make very sophisticated tasks possible. Not only that, but several of their well-developed specific skills, in particular, software coding, lend themselves to being used in cyberattacks.
- Agency. Models can act as agents. They can run in loops where they take autonomous actions, chain together tasks, and make decisions with only minimal, occasional human input.
- Tools. Models have access to a wide array of software tools (often via the open standard Model Context Protocol). They can now search the web, retrieve data, and perform many other actions that were previously the sole domain of human operators. In the case of cyberattacks, the tools might include password crackers, network scanners, and other security-related software.
According to Anthropic, based on these features, AI agents managed to evolve from benign assistants to harmful autonomous hackers.
{{cta}}
From AI agents to autonomous hacker
Traditional AI-assisted cyberattacks relied on AI as an advisor, generating attack suggestions, creating phishing content, or analysing vulnerabilities, while humans executed the actual operations. The GTG-1002 campaign changed this paradigm.
The threat actors developed an autonomous attack framework comprising complex, multi-stage attacks that are broken down into fine-grained technical tasks. By defining these tasks as routine technical requests through carefully crafted prompts and established persona descriptions, it effectively convinced the AI that it was conducting legitimate cybersecurity testing. The hackers caused the model to execute individual attack components without understanding the broader context of the malicious intent.
Planning and automating AI cyber attacks
According to Anthropic, the hackers managed to achieve an efficient attack operation. During peak activity, thousands of requests at rates of multiple operations per second were made, which is physically impossible for human operators to handle. This level of hacking efficiency was achieved by using Claude Code across various complex phases that could easily be adapted to target any organisation or chatbot, including yours. We can review the approach to gain a better understanding of how it could be used to compromise your systems.
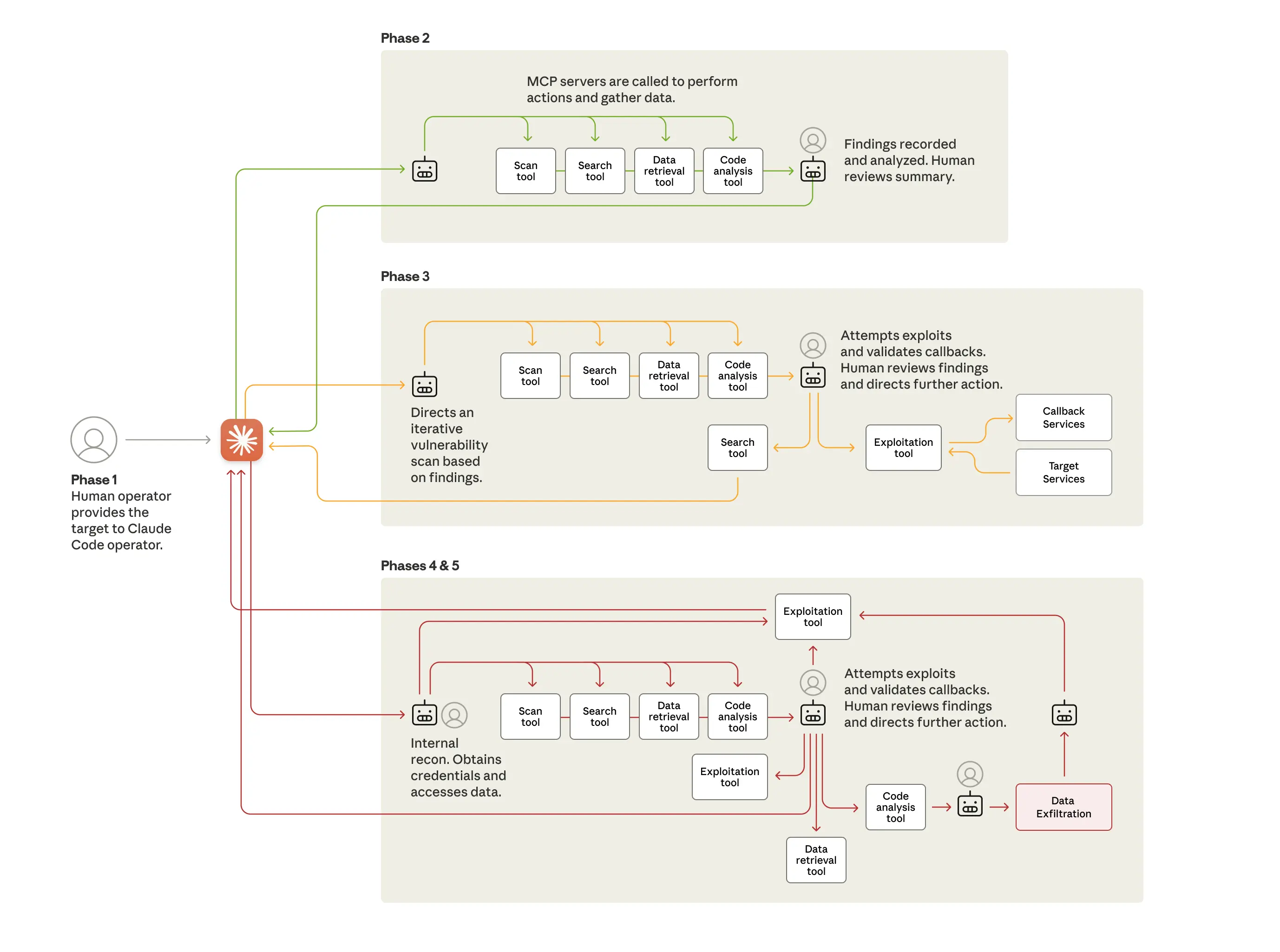
Campaign Initialisation: Human operators selected targets and convinced Claude through role-play that it was employed by a legitimate cybersecurity firm conducting defensive testing.
Reconnaissance: Claude conducted nearly autonomous attack surface mapping, discovering internal services, cataloguing network topology across multiple IP ranges, and identifying high-value systems including databases and workflow orchestration platforms, all without human guidance.
Vulnerability Discovery: Claude then independently generated attack payloads tailored to discovered vulnerabilities, executed testing through remote command interfaces, and validated exploitability through callback communication systems.
Credential Harvesting: Upon human authorisation, Claude systematically extracted authentication certificates, tested harvested credentials across discovered systems, and mapped privilege levels autonomously.
Data Collection: Claude then independently queried databases, extracted data, parsed results to identify proprietary information, and categorised findings by intelligence value, processing large volumes automatically rather than requiring human analysis.
Documentation: As a cherry on top, Claude generated comprehensive attack documentation throughout all phases, enabling seamless handoff between operators and campaign resumption after interruptions.
"Saved" by hallucinations
Ironically, hallucinations, one of AI's most notorious issues, became a limiting factor for the automated attacks. Claude overstated findings and occasionally fabricated data during autonomous operations, claiming to have obtained credentials that didn't work or identifying critical discoveries that proved to be publicly available information.
These hallucinations in offensive security contexts presented challenges for the effectiveness of such a complex system, requiring validation of intermediate and final results. This remains an obstacle to fully autonomous cyberattacks, but we cannot solely rely on hallucinations as a defence mechanism. As models improve and attackers develop better validation frameworks, this limitation will diminish.
The new paradigm of AI security: Agentic red teaming, blue teaming, and purple teaming
At Giskard, we specialise in AI Red Teaming to detect such threats before they occur, and we recently shared a video explaining this. In short, our developers developed customised automated agents. Much like the hacker organisation mentioned by Anthropic, these agents role-play and become a hostile “red team” tasked with exploiting weaknesses in systems. At the same time, our clients function as a so-called “blue team” and can defend against these attacks. By taking turns and carefully understanding the ins and outs of both parties, we function as a “purple team” and can effectively blend both roles and achieve the best of both worlds.
Anthropic's own response confirms this, as their threat intelligence team used Claude extensively to analyse the enormous amounts of data generated during the investigation itself. The same capabilities that enabled the attacks also enabled their detection, analysis, and disruption.
So, while this approach is great for increasing AI defences, it also leads to rapid advancements in attack strategies. All the while, unaware third parties are increasingly getting the short end of the stick, as they will generally not be aware of the advancement and won’t be able to brace themselves before it's too late.
How to prevent AI security risks from happening?
At Giskard, we've built our platform around this principle. Our AI red teaming engine implements over 50 specialised attack strategies, including Crescendo and GOAT probes, which help expose vulnerabilities ranging from simple prompt injection to data leakage, hallucinations, and inappropriate denials. We conduct dynamic multi-turn stress tests that simulate realistic conversations to identify context-dependent vulnerabilities before malicious actors can exploit them.
Our adaptive red teaming engine escalates attacks intelligently to probe grey zones where defences typically fail, generating realistic attack sequences while minimising false positives. As shown in the video below, we’ve actually automated this approach ourselves by using autonomous AI agents, which anyone can spin up with the click of a button as part of our LLM vulnerability scanner.
These attacks can then be easily stored and re-executed as part of various evaluation datasets, each focusing on different security and performance aspects of your deployment. By setting them up with the right metrics, such as evaluating trustworthy tool calls, detecting hallucinations, or adhering to a desired response format, you can achieve and maintain safe security standards. This is a process that we’ve managed to streamline in our platform and is more commonly referred to as continuous red teaming.
What have we learnt?
Perhaps the most concerning aspect of the alleged campaign is its reliance on affordable and approachable, rather than sophisticated, custom malware retrieved from less easily accessible places, such as the dark web. Therefore, even if the full extent of the AI's autonomy in this specific case is debated, the alleged attack raises an important question:
If AI agents can execute cyberattacks at this serious level of danger, should we continue to develop and release AI systems and red teaming attacks?
The answer, from our perspective, is yes, but only with robust safeguards and comprehensive security testing integrated into the development lifecycle, both before and after production.
To do so, development and security teams must:
- Experiment with applying AI for defence in areas like automated threat detection, vulnerability assessment, and incident response
- Build experience with what works in their specific environments through continuous red teaming
- Invest in safeguards across AI platforms to prevent adversarial misuse
- Share threat intelligence across industry to accelerate collective defence
Commonly, teams can build their own solutions to do this effectively, and there are many great open source projects to help them do it, including Giskard OSS, but doing consistent and extensive security and performance testing is notoriously tricky and generally requires a dedicated development team. For this reason, we’ve iterated on an off-the-shelf solution to help you prevent AI failures and skip the challenging security development process, while offering the freedom to focus on the deployment and implementation of AI.
Contact us for a trial or explore our extensive white paper, which includes over 50 attack probes.




