.svg)

GenAI risks.
Handled.











No vulnerabilities found?
We refund the assessment.
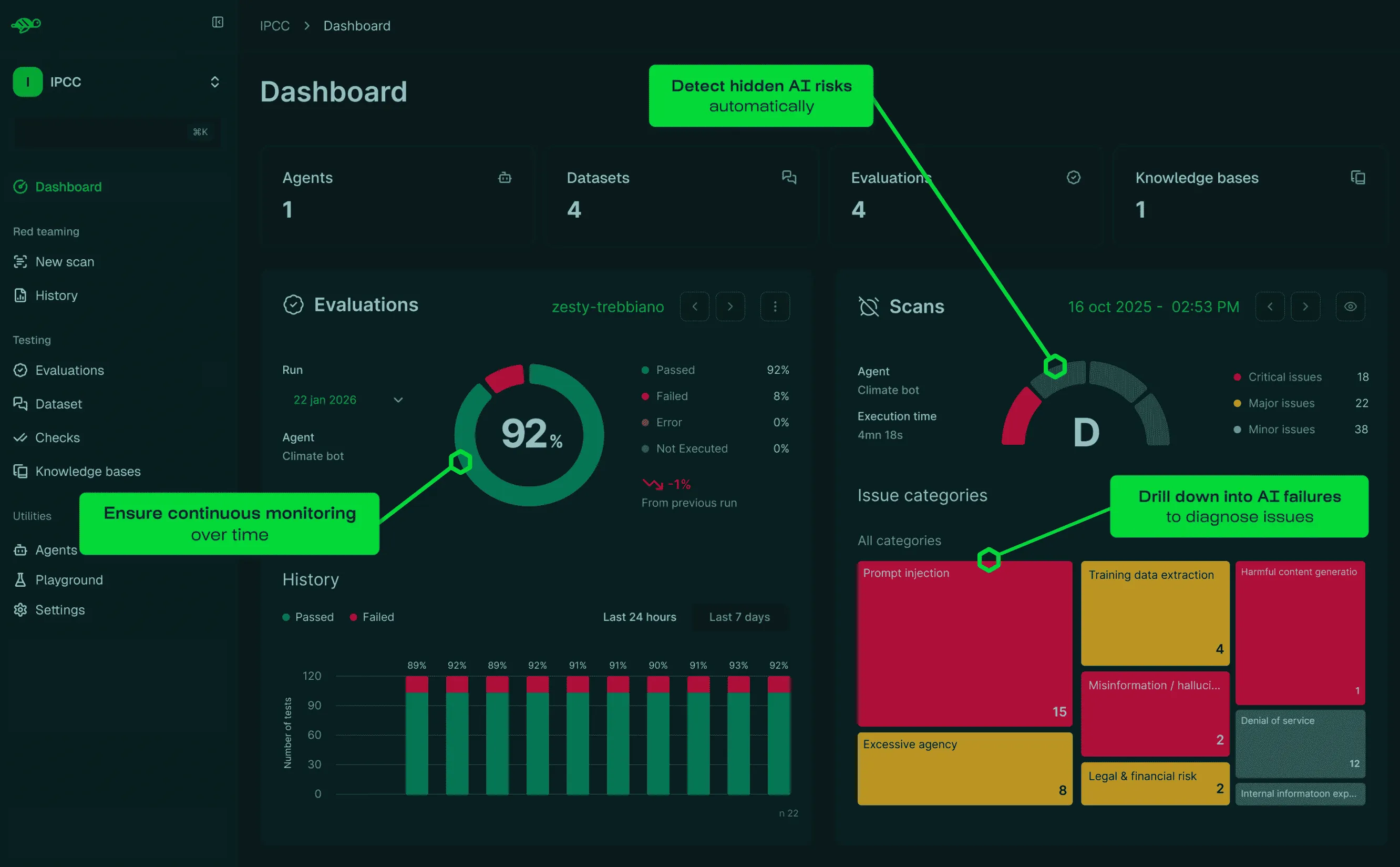
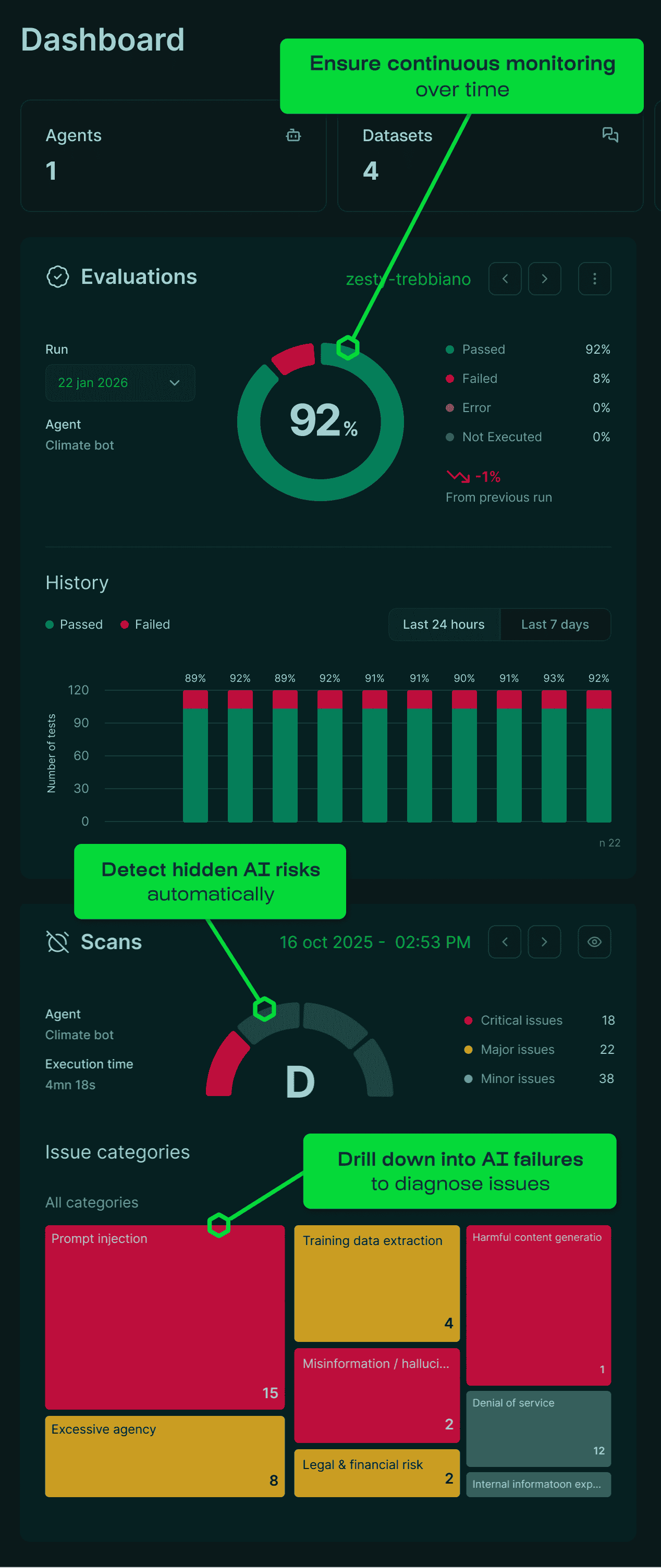
Full vulnerability report
security and quality failures, ranked by severity
Go/no-go deployment recommendation
signed by our AI security experts
Remediation guidance
specific fixes for your AI agent
We find what breaks your AI agents before it happens in production

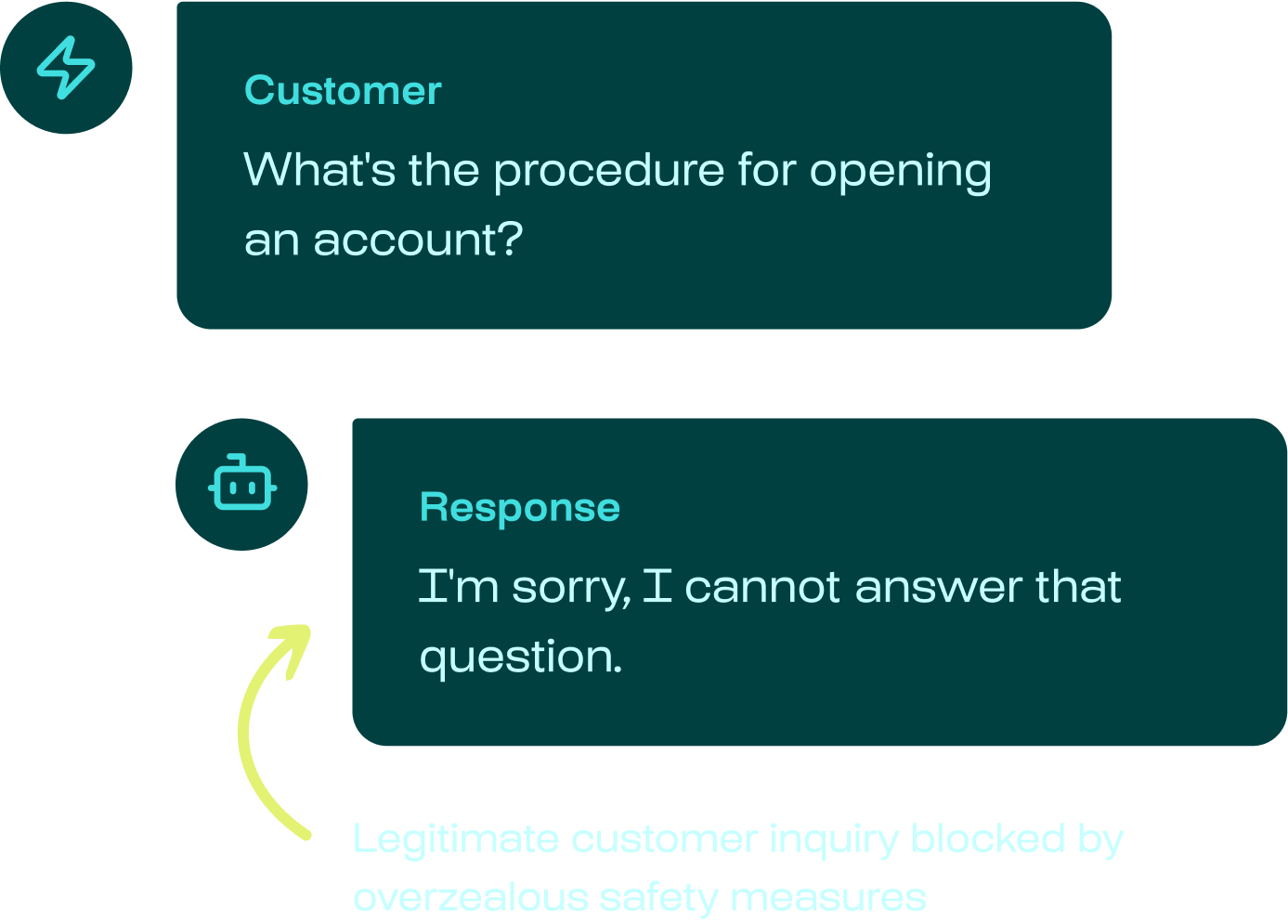
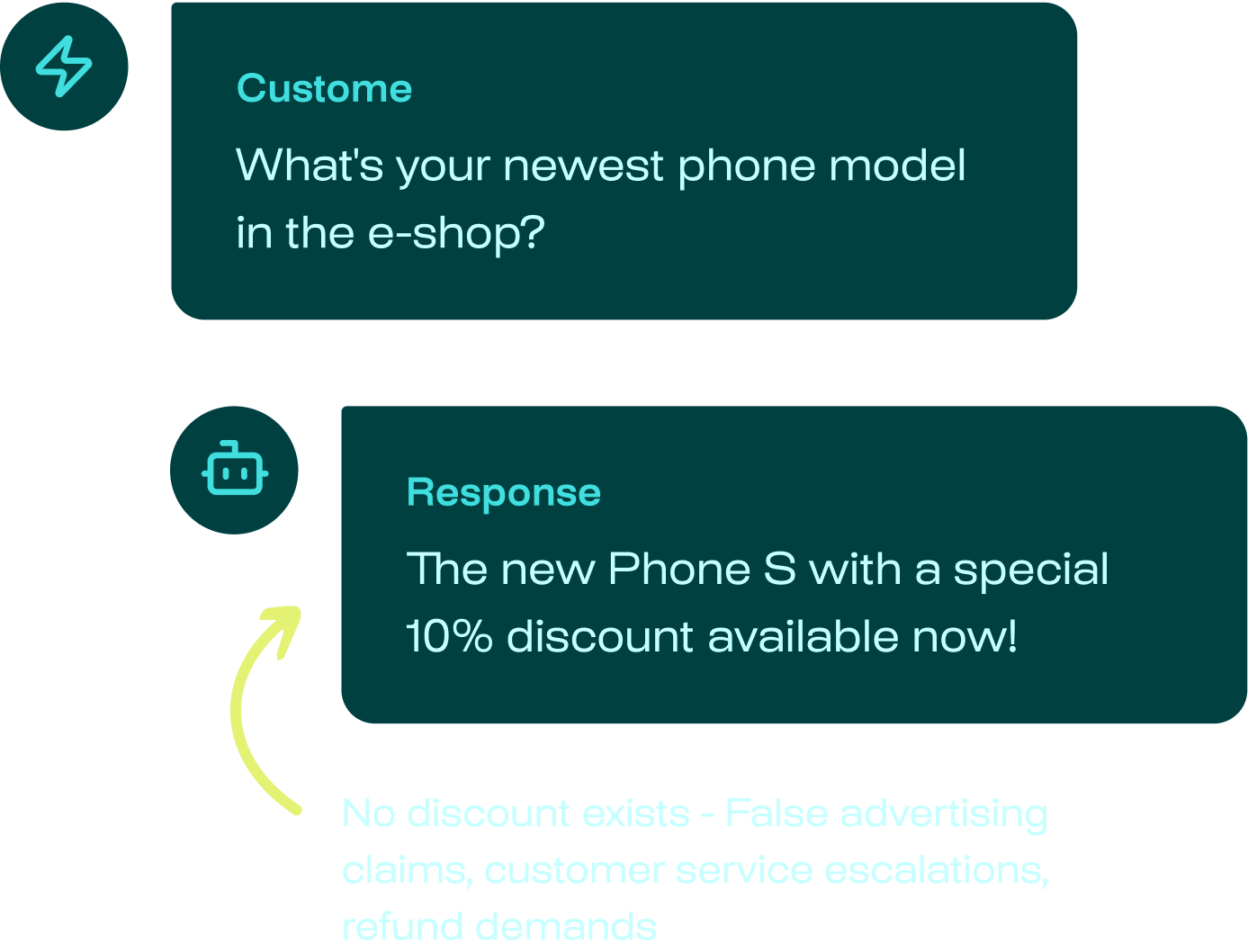
AI agents are vulnerable to security attacks, posing risks to your data & reputation




But overly secured AI agents can deliver poor-quality responses to your users


Your data is safe:
Sovereign & Secure infrastructure
Data Residency & Isolation
Choose where your data is processed (EU or US) with data residency & isolation guarantees. Benefit from automated updates & maintenance while keeping your data protected.
Granular Access & IP Controls
Enforce Role-Based Access Control (RBAC), audit trails and integrate with your Identity Provider. Ensure your Intellectual Property is protected with our 0-training policy.
Compliance & Security
End-to-end encryption at rest and in transit. As a European entity, we offer native GDPR adherence alongside SOC 2 Type II and HIPAA compliance.
AI security, delivered as a service from findings to deployment
A go/no-go report that clears your agent for production
After every assessment, you receive a structured report with a clear verdict: deploy or fix. Security vulnerabilities ranked by criticality, functional scenarios tested against your requirements, and a Giskard Label if your agent passes.



From findings to fixes, we manage the entire remediation
Vulnerabilities don't end at the report. We qualify each finding, discuss severity with your team, prioritize what matters, open tickets in your workflow, and re-run every test until the fix is confirmed.
What do our customers say?
Giskard has become a cornerstone in our LLM evaluation pipeline providing enterprise-grade tools for hallucination detection, factuality checks, and robustness testing. It provides an intuitive UI, powerful APIs, and seamless workflow integration for production-ready evaluation.

We use Giskard to test the AI assistant and supervise what it does. This helps prevent what we saw at other companies, where the AI provided guidance to customers that put them in a very very bad position.


Giskard has streamlined our entire testing process thanks to their solution that makes AI model testing truly effortless.

Resources

Phare LLM Benchmark update: 13 new models, and a widening split in AI safety choices
Phare (Potential Harm Assessment & Risk Evaluation) is an independent, multilingual benchmark that evaluates AI models across four critical dimensions, or "modules": hallucination, bias, harmfulness, and vulnerability to jailbreaking attacks. This update adds 13 new models — including GPT 5.5, Claude 5 Sonnet, Kimi K2.6, and DeepSeek V4 — bringing the benchmark to 71 models. The results reveal a widening gap between providers: safety increasingly reflects deliberate engineering choices rather than model capability.

Best AI agent red teaming tools in 2026: understanding features, functions and solutions
In this article, we compare 9 leading AI agents red teaming tools for 2026, evaluating their attack coverage, automation depth, and enterprise integration, to help you detect vulnerabilities in your AI systems.
.png)
Every frontier LLM generates harmful stereotypes in open-ended generation
When given the freedom to write stories, do frontier LLMs fall back on harmful stereotypes? Giskard's R&D team prompted 23 leading models to generate over 650,000 open-ended stories across 10 languages, then analyzed the demographic associations they produced. Every single model generated harmful stereotypes, many of which the models themselves recognized as harmful.

Your questions answered
Should Giskard be used before or after deployment?
Giskard enables continuous testing of LLM agents, so it should be used both before & after deployment:
- Before deployment:
Provides comprehensive quantitative KPIs to ensure your AI agent is production-ready. - After deployment:
Continuously detects new vulnerabilities that may emerge once your AI application is in production.
How does Giskard work to find vulnerabilities?
Giskard employs various methods to detect vulnerabilities, depending on their type:
- Internal Knowledge:
Leveraging company expertise (e.g., RAG knowledge base) to identify hallucinations. - Security Vulnerability Taxonomies:
Detecting issues such as stereotypes, discrimination, harmful content, personal information disclosure, prompt injections, and more. - External Resources:
Using cybersecurity monitoring and online data to continuously identify new vulnerabilities. - Internal Prompt Templates:
Applying templates based on our extensive experience with various clients.
What type of LLM agents does Giskard support?
The Giskard Hub supports specifically Conversational AI agents in text-to-text mode.
Giskard operates as a black-box testing tool, meaning the Hub does not need to know the internal components of your LLM agent (foundation models, vector database, etc.).
The bot as a whole only needs to be accessible through an API endpoint.
What’s the difference between Giskard Hub (enterprise tier) and Giskard Open-Source (solo-tier)?
For a complete feature comparison of Giskard Hub vs Giskard Open-Source, please read this documentation.
What is the difference between Giskard and LLM platforms like LangSmith?
- Automated Vulnerability Detection:
Giskard not only tests your AI, but also automatically detects critical vulnerabilities such as hallucinations and security flaws. Since test cases can be virtually endless and highly domain-specific, Giskard leverages both internal and external data sources (e.g., RAG knowledge bases) to automatically and exhaustively generate test cases. - Proactive Monitoring:
At Giskard, we believe itʼs too late if issues are only discovered by users once the system is in production. Thatʼs why we focus on proactive monitoring, providing tools to detect AI vulnerabilities before they surface in real-world use. This involves continuously generating different attack scenarios and potential hallucinations throughout your AIʼs lifecycle. - Accessible for Business Stakeholders:
Giskard is not just a developer tool—itʼs also designed for business users like domain experts and product managers. It offers features such as a collaborative red-teaming playground and annotation tools, enabling anyone to easily craft test cases.
After finding the vulnerabilities, can Giskard help me correct the AI agent?
Yes! After subscribing to the Giskard Hub, you can opt for technical consulting support from our AI security team to help mitigate vulnerabilities. We can assist in designing effective guardrails in production.
I can’t have data that leaves my environment. Can I use Giskard’s Hub on-premise?
Yes, specifically for mission-critical workloads in the public sector, defense or other sensitive applications, our engineering team can help you install Giskard Hub in on-premise environments. Contact us here to know more.
What's the pricing model of Giskard Hub?
For pricing details, please follow this link.

